1. SLAM综述_2020_Baichuan_Huang

2. 摘要
文章对激光SLAM,视觉SLAM以及它们的融合进行回顾。对于激光或者视觉slam而言,文章阐述了传感器的基本类型和产品、开源系统的种类和历史,深度学习的嵌入,挑战以及未来。另外的,视觉惯性里程计VIO也有被提及。对于激光和视觉融合的SLAM,本文重点提到了关于多传感器的标定,硬件、数据、任务层级的融合。最后,文章讲述了一些开放的问题以及前言的思考。文章的贡献可总结如下:
- 提供了SLAM领域高质量和全面的overview
- 对于新入门的研究者十分容易的理解SLAM的发展历史
- 可作为一部SLAM词典供研究者
3. 介绍
SLAM的主要任务:定位和建图。 1990年,“Randall Smith, Matthew Self, and Peter Cheeseman. Estimating un-certain spatial relationships in robotics. InAutonomous robot vehicles,pages 167–193. Springer, 1990.”首先提出了利用EKF进行增量式的位姿和地图估计,事实上,从未知环境的未知位置出发,机器人在运动过程中通过反复观察环境特征来确定自己的位置和姿态,然后根据周围环境的位置,绘制出一幅递增的周边环境地图。定位是近年来一个非常复杂和热点的问题。定位技术取决于环境和对成本、精度、频率和鲁棒性的要求,可以通过gps(全球定位系统)、IMU(惯性测量单元)和无线信号等来实现。但GPS只能在户外工作,IMU系统存在累积误差[5]。无线技术作为一种主动系统,无法在成本和精度之间取得平衡。近年来,随着激光雷达、相机、IMU等传感器的迅速发展,SLAM系统应运而生
从基于滤波器的SLAM开始,目前基于图优化的SLAM占据主导地位,该算法由卡尔曼滤波(KF)、EKF和粒子滤波(PF)演化为基于图的优化算法,该算法由卡尔曼滤波(KF)、EKF和粒子滤波(PF)演化为基于图的优化算法。SLAM技术也从最早的军事原型发展到后来多传感器融合的机器人应用。
4. 激光SLAM
4.1. 激光传感器
激光传感器分为2D和3D激光雷达,具体区分是以传感器的激光束数量来定义。在生产过程中,激光雷达也可以分为机械雷达、MEMS (micro- electromechanical)等混合固态激光雷达和固态激光雷达。固态激光雷达可以通过相控阵技术和flash技术来实现。
- Velodyne:在机械激光雷达,它有VLP-16, HDL - 32E和HDL-64E。在混合固态激光雷达,它有Ultra Puck auto-32E
- SLAMTEC:低成本激光雷达和机器人平台,如RPLIDAR A1, A2和R3
- Ouster:16到128线的机械激光雷达
- Quanergy:S3是世界上第一个发布的固态激光雷达,M8是机械激光雷达。S3-QI是微小型固态激光雷达
- Ibeo:在机械激光雷达中,有Lux 4L和Lux 8L。与Valeo公司合作,它发布了一款名为Scala的混合固态激光器
在未来的发展趋势中,小型化、轻量化的固体无级变速器将会占据市场并满足大多数的应用,其他激光雷达公司包括但不限于sick, Hokuyo, HESAI, RoboSense, LeddarTech, ISureStar, benewake, Livox, Innovusion, Innoviz, Trimble, LeishenIntelligent System
4.2. SLAM
激光SLAM在理论和实际应用中是可靠的。《概率机器人》阐述了基于概率的二维激光雷达同步定位与建图的数学理论。“An evalu-ation of 2d slam techniques available in robot operating system”对2D激光SLAM做了一个综述。
4.2.1. 2D 激光SLAM
Gmapping:它是基于RBPF(Rao-Blackwellisation Partical Filter)方法的机器人中最常用的SLAM包,使用了扫描匹配(Scan matching)方法来估计位置(《概率机器人》、Improvedtechniques for grid mapping with rao-blackwellized particle filter.2007)。它是基于占据地图的FastSLAM的进阶版本。
HectorSlam:使用扫描匹配(Scan matching)和IMU传感器实现了结合2D SLAM和3D导航。(A flexible and scalable slam system with full 3d motionestimation.2011)
KartoSLAM:一种基于图的SLAM系统(Efficient sparse pose adjustmentfor 2d mappin.2010)
LagoSLAM:基于图的SLAM,讨论了非线性非凸的损失函数。(A linear approximation for graph-based simultaneous localization andmapping.2012)
CoreSLAM/Tiny SLAM:可以理解为性能损失最小的算法(A slam algorithm in less than200 lines c-language program.2010)

Cartographer:Google的SLAM系统,采用了子图和回环检测技术达到了最好的产品级别性能。算法可以提供2D和3D的多平台和传感器配置。( Real-time loop closure in 2d lidar slam.2016)
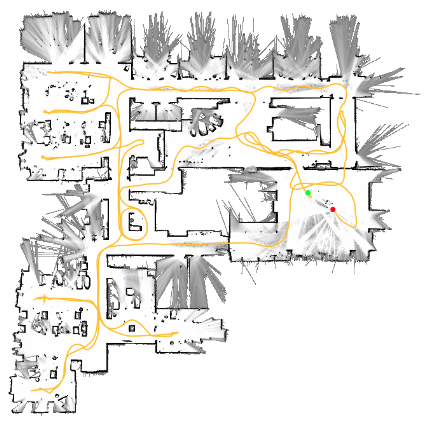
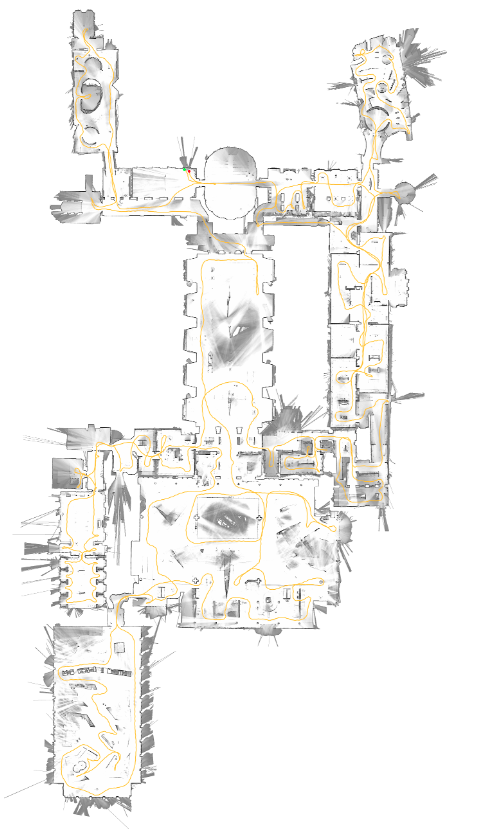
4.2.2. 3D 激光SLAM
Loam:是一种利用三维激光雷达进行状态估计和建图的实时方法。它也有前后旋转版本和连续扫描2D激光雷达版本(Loam: Lidar odometry and mapping inreal-time.2014)
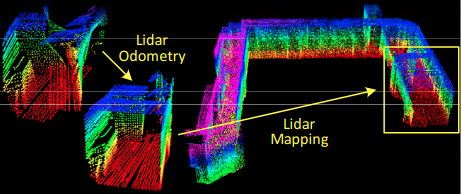
Lego-Loam:采用点云从VelodyneVLP-16激光雷达(水平放置)和(可选的)IMU作为数据输入。系统实时输出6D位姿估计,具有全局最优化和回环检测功能。(Lego-loam: Lightweight and ground-optimized lidar odometry and mapping on variable terrain 2018)


Cartographer:支持2D和3D SLAM
IMLS-SLAM:基于(扫描-模型匹配)框架,提出了一种基于三维激光雷达数据的低漂移SLAM算法(Imls-slam: scan-to-model matching basedon 3d data.2018)
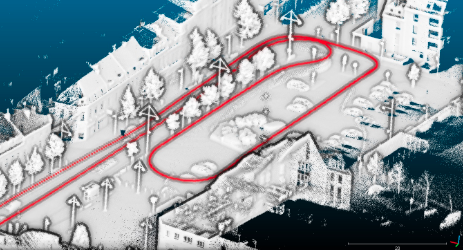

4.2.3. 深度学习Deep Learn在激光SLAM中的应用
特征提取和检测:
PointNetVLAD——提供了端到端的训练以及推理来实现从给定的3D点云中提取全局描述符,解决基于点云的位置识别检索问题(ointnetvlad: Deeppointcloud based retrieval for large-scale place recognition)。
VoxelNet——一个通用的三维检测网络,它将特征提取和边界框预测统一到一个单阶段模型,端到端可训练的网络(Voxelnet: End-to-end learning for pointcloud based 3d object detection.)
BirdNet、LMNet:描述了效率的单阶段卷积神经网络,用来检测物体病输出一个对象映射和每个点的边界框偏移值。
PIXOR:是一个无提议的单阶段检测器,它从像素级别的神经网络中进行解码,输出3D物体的姿态估计(Pixor: Real-time 3d objectdetection from point clouds)
Yolo3D:基于2D透视图像空间中单阶段回归架构的成功,将其扩展到从激光雷达点云生成定向三维物体边界盒(Yolo3d: End-to-end real-time 3d oriented objectbounding box detection from lidar point cloud)
PointCNN:提出了从输入点云中学习X变换,X变换应用于典型卷积(点乘)运算符的元素-向量积和求和运算(Pointcnn: Convolution on x-transformed points.)
MV3D:将激光雷达点云和RGB图像作为输入,并预测带姿态方向的的3D边界框(Multi-view3d object detection network for autonomous driving)
PU-GAN:提出一种新的点云上采样网络,基于generative adversarial network (GAN),其他类似的工作可以参考CVPR2018等最佳论文。( Pu-gan: A point cloud upsampling adversarial network.)
识别与分割
实际上,对三维点云的分割方法可以分为基于边缘、区域生长、模型拟合、混合方法,机器学习和深度学习方法。(A review of point cloudssegmentation and classification algorithms)
PointNet:设计了一种直接利用点云的新型神经网络,具有分类、分割和语义分析的功能(Pointnet:Deep learning on point sets for 3d classification and segmentation)
Point-Net++:通过增加上下文的规模来获得层次特征(Pointnet++: Deephierarchical feature learning on point sets in a metric space.)
VoteNet:构建点云三维检测pipline作为端到端三维目标探测网络,基于Point-Net++。(eephough voting for 3d object detection in point clouds)
SegMap:基于3D点云的语义分割作为一种SLAM问题中的地图表示(SegMap: 3d segment mapping usingdata-driven descriptors. )
SqueezeSeg:使用循环CRF (Conditionalrandom fields)进行实时道路目标分割的三维激光雷达点云的卷积神经网络 (queezeseg:Convolutional neural nets with recurrent crf for real-timeroad-objectsegmentation from 3d lidar point cloud. / queezesegv2: Improved model structure and unsuperviseddomain adaptation for road-object segmentation from a lidar pointcloud / A lidar point cloud generator: from a virtualworld to autonomous driving )
PointSIFT:一个三维点云的语义分割框架,它基于一个简单的模块,从八个方向的邻域点提取特征。(Pointsift: A sift-like network module for 3d point cloud semanticsegmentation.)
PointWise:提出了一种基于三维点云的语义分割和目标识别的神经网络(Pointwise convo-lutional neural networks.)
3P-RNN:(3d recurrent neural networks with context fusion for point cloudsemantic segmentation. )提出了一种基于两水平方向的非结构化点云语义分割的端到端方法,利用了云的上下文特征,其他类似的工作如SPG 以及 综述(A review of point cloudssegmentation and classification algorithms.)
SegMatch:基于3D 分割(线段?)的检测和匹配的回环检测方法。(Segmatch: Segment based place recognitionin 3d point clouds. )
Kd-Network:专为三维模型识别任务和工作与非结构化点云( Escape from cells: Deep kd-networks for the recognition of 3d point cloud models)
DeepTempo-ralSeg:提出了一种基于深度卷积神经网络(DCNN)的激光雷达语义分割算法(eeptemporalseg: Temporallyconsistent semantic segmentation of 3d lidar scans)
LU-Net:实现了语义分割的功能,代替了传统的全局三维分割方法(Lu-net: An efficient network for 3d lidar pointcloud semantic segmentation based on end-to-end-learned 3d featuresand u-net) ,其他类似的工作如 PointRCNN (Pointrcnn: 3d ob-ject proposal generation and detection from point cloud.)
定位
L3-Net:是一种新的基于学习的激光雷达定位系统,达到厘米级定位精度(L3-net: Towards learning based lidar localization for autonomous driving.2019)[This work is supported by Baidu Autonomous DrivingBusiness Unit (Baidu ADU) in conjunction with the ApolloProject (http://apollo.auto/)]
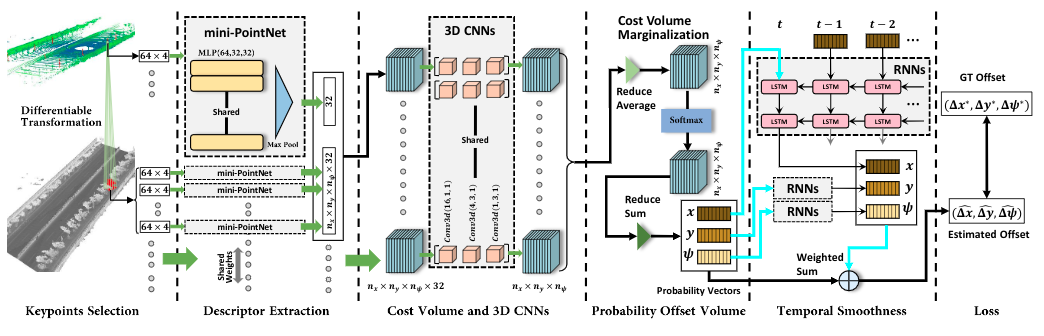
SuMa++:在像素点云级别标签基础上为全部扫描计算语义分割结果,允许我们建立语义丰富的图元标签地图,利用语义约束改进投影扫描匹配(Suma++:Efficient lidar-based semantic slam 2019) 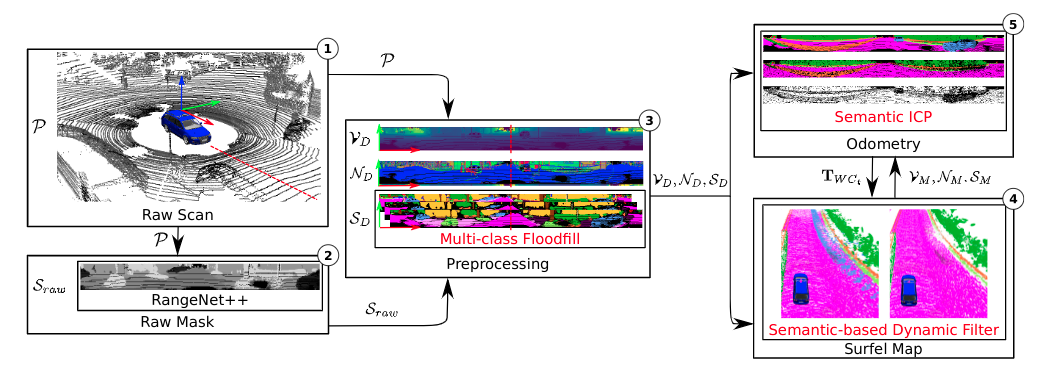
- 挑战和未来
- 成本和适应性:激光雷达的优点是可以提供三维信息,不受夜晚和光线变化的影响,另外,视角相对较大,可以达到360度。但是,激光雷达的技术门槛很高,发展周期长,成本大。未来的发展趋势是小型化、合理化、固态、高可靠性和适应性
- 低纹理和动态环境:大多数SLAM系统只能在一个固定的环境下工作,但事情总是在不断变化。此外,长走廊、大管道等低结构环境会给激光雷达SLAM带来麻烦。(Imu-assisted 2d slam method for low-texture and dynamic environments)使用IMU协助2D SLAM来解决上面的问题。(Dynamic pose graph slam: Long-term mapping in lowdynamic environments)在绘图过程中加入时间维度,使机器人在动态环境中工作时能够保持精确的地图。如何使激光雷达对低纹理和动态环境具有更强的鲁棒性,以及如何保持地图的更新是需要深入考虑的问题。
- 对抗传感器攻击:深度神经网络容易受到反样本的攻击,这一点在基于摄像头的感知中也得到了证明。在基于激光的感知中,这是非常重要的,但是还没有被开拓。通过攻击,(Illusionand dazzle: Adversarial optical channel exploits against lidars forautomotive applications.)该算法首先对输出数据和距离估计进行干扰,使得基于VLP-16的激光雷达无法感知某个方向上的距离。(Adversarial sensor attack on lidar-based perception in autonomousdriving.)探索了通过战略控制来愚弄机器学习模型的可能性,把它看作一个优化问题,根据输入的扰动函数和目标函数进行建模,这将攻击成功率提高到大约75%。对抗式的传感器攻击将对基于激光雷达点云的SLAM系统进行欺骗,是无形的,很难被发现和保护在这种情况下,如何防止激光SLAM系统受到敌方传感器的攻击应该成为一个新的课题。
5. 视觉SLAM
随着CPU和GPU的发展,图形处理的能力越来越强大,相机传感器变得更便宜,更轻,同时更多功能。过去的十年见证了视觉SLAM的飞速发展。视觉SLAM使用相机也使系统更便宜和更小,和激光SLAM相比,视觉SLAM系统可以在微PC和嵌入式设备上运行,甚至可以在智能手机等移动设备上运行。
- a versatile and accurate monocular slam system.
- Vins-mono: A robust andversatile monocular visual-inertial state estimator
- Parallel tracking and mapping on acamera phone ery High Frame Rate Volumetric Integration ofDepthImages on Mobile Device.
- Get out of my lab: Large-scale, real-time visual-inertial localization.)
视觉SLAM包括传感器数据的收集(如相机或惯性测量单元),前端的:视觉里程计、视觉惯性里程计, 后端的:回环检测和优化,建图。《视觉SLAM 14讲》。重定位模块是增加稳定性和准确率的模块。(Visual slamalgorithms: A survey from 2010 to 2016)
在视觉里程计中,除了基于特征或模板匹配的方法,或相关方法来确定相机的运动,还有一种方法依赖于傅里叶-梅林变换(An fft-based techniquefor translation, rotation, and scale-invariant image registration.)。 文献(Visual odometry based on thefourier-mellin transform for a rover using a monocular ground-facingcamera)和(Visualodometry based on the fourier transform using a monocular ground-facing camera)给出了一个在没有明显视觉特征的环境下,使用面向地面的相机的例子。
5.1. 视觉传感器
照相机可分为单目照相机、立体照相机、RGB-D照相机、事件照相机等
- 单目相机:基于单目摄像机的视觉slam对真实大小的轨迹和地图有一个比例尺。也就是说,单目相机无法获得真实的深度,这就是所谓的尺度模糊。(A survy of monocularsimultaneous localization and mapping,2016)。基于单目摄像机的SLAM必须进行初始化,并面临漂移问题
- 立体相机:立体摄像机是由两个单目摄像机组合而成,但两个单目摄像机之间的基线距离是已知的,虽然深度可以通过校准、校正、匹配和计算得到,但这个过程是浪费资源的
- RGB-D camera:RGB-D相机也称为深度相机,相机可以直接以像素输出深度,深度相机可以通过立体、结构光和TOF技术来实现。结构光理论是指红外激光对物体表面发出具有结构特征的图案,然后红外相机将收集由于不同深度的表面图案的变化,然后红外相机将收集由于不同深度的表面图案的变化。
- 事件相机:(Event-based vision: A survey. 2019)事件相机不是以固定的速率捕获图像,而是异步地测量每个像素的亮度变化,事件相机有非常高的动态范围(140 dB vs. 60 dB),高时间分辨率(按us的顺序),低功耗,不受运动模糊的影响。因此,事件相机在高速、高动态范围内的性能优于传统相机。以动态视觉传感器为例,(A 128x128 120db 15us latency asynchronous temporal contrast vision sensor. / a 640×480 dynamic vision sensor with a 9μm pixel and 300meps address-event representation / A microbolometer asynchronous dynamicvision sensor for lwir./ sparc-compatible general purpose address-event processor with 20-bit l0ns-resolution asynchronous sensor data interface in 0.18μm cmos.)
接下来介绍视觉传感器的产品和公司:
- Microsoft: Kinectc v1(structured-light), Kinect v2(TOF),Azure Kinect(with microphone and IMU)
- Intel:200 Series, 300 Series, Module D400 Series,D415(Active IR Stereo, Rolling shutter), D435(Active IRStereo, Global Shutter), D435i(D435 with IMU)
- Stereolabs ZED:ZED Stereo camera(depth up to 20m)
- MYNTAI:D1000 Series(depth camera), D1200(for smartphone), S1030 Series(standard stereo camera)
- Occipital Structure:Structure Sensor(Suitable for ipad)
- Samsung:Gen2 and Gen3 dynamic vision sensors andevent-based vision solution
其他深度相机还有:Leap Motion,Orbbec Astra,Pico Zense,DUO,Xtion,Camboard,IMI,Humanplus,PERCIPIO,Prime-Sense. 事件相机有:toiniVation,AIT,SiliconEye,Prophesee,CelePixel,Dilusense。
5.2. 视觉SLAM系统
利用图像信息的方法可分为直接法和基于特征的方法,直接法产生半密度和稠密构造,而基于特征的方法产生了稀疏构造
5.2.1. 稀疏视觉SLAM:
MonoSLAM:(单目)第一个实时单目SLAM,基于EKF(Monoslam: Real-time single camera slam.2007) 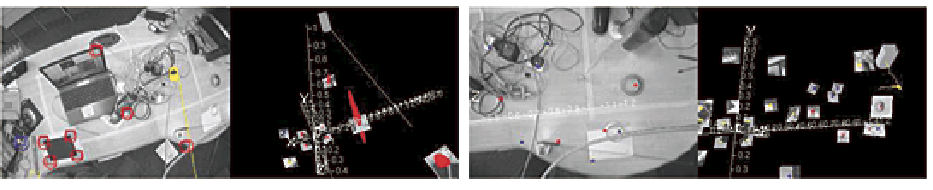
PTAM:(单目)第一个并行跟踪和建图的SLAM系统。首先采用了BA优化和关键帧的概念(Parallel tracking and mapping forsmall ar workspaces. 2007),后一个版本支持一个简单但有效的重定位方法(Improving the agility of keyframe-based slam.2008) 
ORB-SLAM:(单目)使用三个线程:跟踪、Local mapping和闭环检测(Orb: An efficient alternative to sift or surf,2011); ORB-SLAM v2:支持单目,立体相机,和深度相机(Orb-slam2: An open-source slamsystem for monocular, stereo, and rgb-d cameras.2016); CubemapSLAM:一个单目的鱼眼相机SLAM系统,基于ORB-SLAM。Visual Inertial ORB-SLAM:阐述了IMU的初始化过程和可视化信息的联合优化(isual-inertial monocular slamwith map reuse. / On-manifold preintegration for real-time visual–inertial odom-etry.) 
proSLAM:(立体相机)这是一个轻量级的视觉SLAM系统,易于理解(ProSLAM: GraphSLAM froma Programmer’s Perspective.2017) 
ENFT-sfm:(单目)一种高效的可以在一帧或者多帧视频序列中进行特征点匹配,的特征跟踪方法。其更新版本ENFT-SLAM可以运行在大的场合。(fficient non-consecutive feature tracking forrobust structure-from-motion.2016) 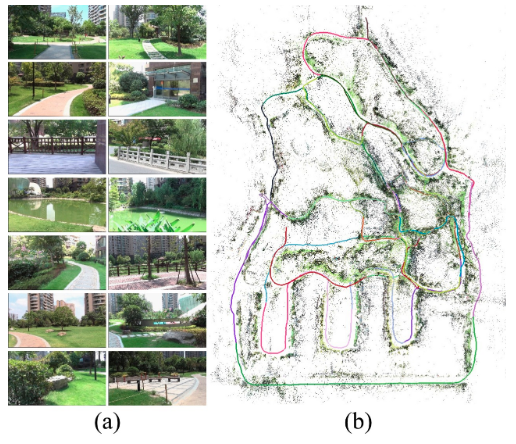
OpenVSLAM:(适用各种相机)基于具有稀疏特征的非直接(间接)SLAM算法。OpenVSLAM的优秀之处在于,该系统支持透视、鱼眼和等矩形,甚至支持您设计的相机模型。(Openvslam: aversatile visual slam framework.2019) 
TagSLAM:意识到SLAM可以用AprilTag,AprilTag是一个视觉基准库,在AR,机器人,相机校准领域广泛使用。通过特定的标志(与二维码相似,但是降低了复杂度以满足实时性要求),可以快速地检测标志,并计算相对位置。此外,它提供了一个前端的GT-SAM因素图优化器,可以设计大量的实验(agslam: Robustslam withfiducial markers.2019) 
5.2.2. 半稠密视觉SLAM
LSD-SLAM:(单目)提出了一种基于李代数和直接法的直接跟踪方法,(Lsd-slam: Large-scale direct monocular slam.2014),(Large-scale directslam with stereo cameras.2015)使其支持立体相机。 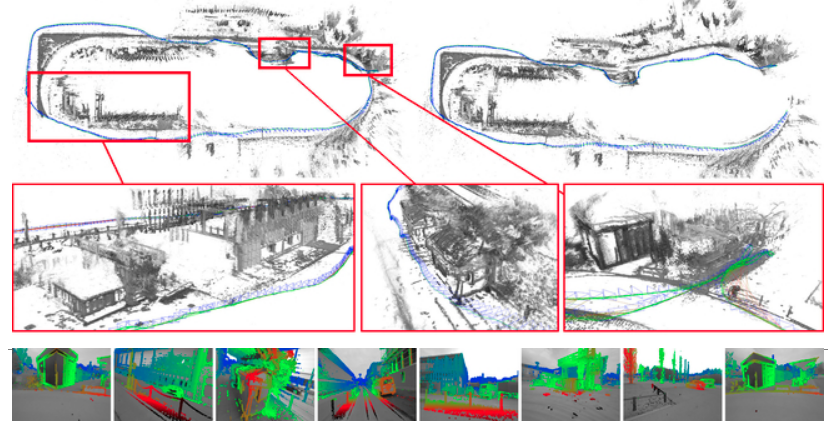

SVO:(单目)半直接法视觉里程计(Svo: Semidirect visual odometry formonocular and multicamera systems.2016)它采用基于稀疏模型的图像对齐来获得更快的速度。其更新的版本扩展应用于鱼眼相机。(On-manifold preintegration for real-time visual–inertial odom-etry.2016)文献给出了关于VIO的详细理论推导和证明。CNN-SVO是一个从单图像深度预测网络中获取深度预测值的SVO版本。 

DSO:(单目)(Direct sparseodometry. 2016 / 2017)是LSD-SLAM作者的另一个新的工作。这是一个不需要检测特征点和描述符的,基于直接法和稀疏法的的视觉里程计。 
EVO:(事件相机)(Evo: A geometric approach to event-based 6-dofparalleltracking and mapping in real time.2016)提出了一种基于事件的视觉里程计算法,算法不受运动模糊的影响,并在具有挑战性的,高动态范围条件下与强烈的照明变化运行得很好。其他的基于事件相机的半稠密SLAM系统可以见(Semi-dense 3d reconstruction with a stereoevent camera.) 
5.2.3. 稠密视觉SLAM
DTAM:(单目)可实时重建3D模型基于最小化全局空间正则化能量函数,使用一种新的非凸优化框架,称之为直接法。(Inversedepth parametrization for monocular slam 2008 / Dtam: Dense tracking and mapping in real-time.2011) 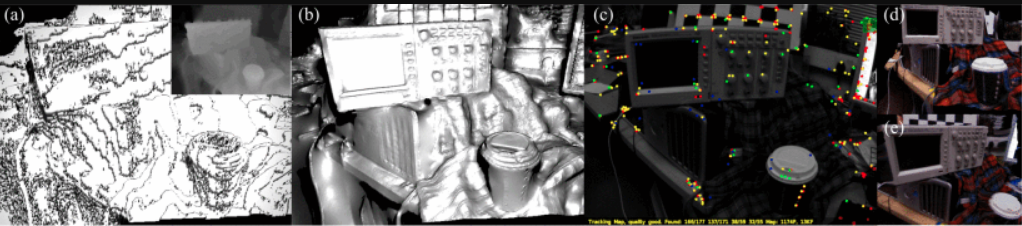
MLM SLAM:(单目)可以不使用GPU在线重建3D稠密模型,其关键贡献在于多分辨率深度估计和空间平滑过程。(Multi-level mapping: Real-time dense monocular slam.2016) 
Kinect Fusion:(RGB-D摄像机)几乎是第一个使用深度相机进行3D重建的系统(Kinectfusion: Real-time dense surface mapping and tracking 2011 / Kinectfusion: real-time 3drecon-struction and interaction using a moving depth camera 2011) 
DVO:(RGB-D相机)提出一种稠密视觉SLAM方法,一种基于熵的关键帧选择和闭环检测的相似度度量方法,使用G2O框架(Real-time visual odometry from dense rgb-d images.2011 / Robust odometryestimation for rgb-d cameras.2013 / Dense visual slamfor rgb-d cameras.2013) 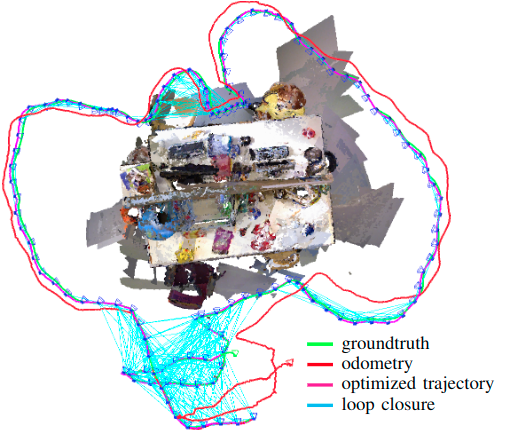
RGBD-SLAM-V2:(RGB-D相机)在不借助其他传感器的情况下重建出准确的三维致密模型(3-d mapping with an rgb-d camera.2014) 
Kintinuous:(RGB-D相机)一个带有实时全局一致的点和网格重构的视觉SLAM系统(Kintinuous: Spatially extendedkinectfusion 2012) 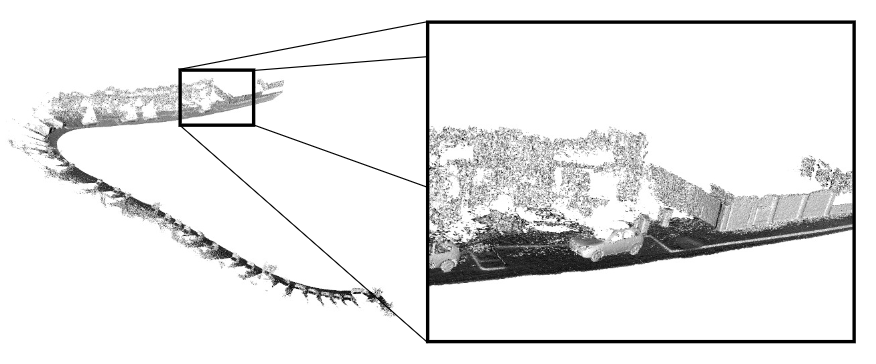
RTAB-MAP:(RGB-D相机)支持SLAM,但难以作为算法开发的基础(Online global loop closuredetection for large-scale multi-session graph-based slam.2014), 其后版本支持了视觉和激光SLAM( Rtab-map as an open-sourcelidar and visual simultaneous localization and mapping library forlarge-scale and long-term online operation.2019) 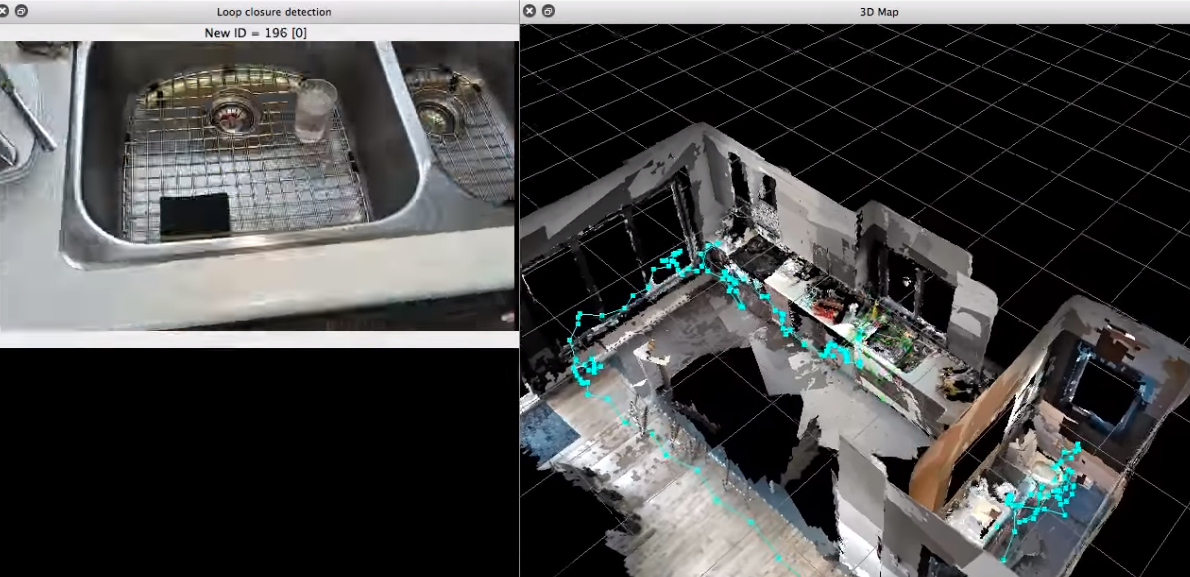

Dynamic Fusion:(RGB-D相机)第一个具有实时重建重建非刚性变形的场景的稠密SLAM系统,基于Kinect Fusion(Dynamicfu-sion: Reconstruction and tracking of non-rigid scenes in real-time.2015)。VolumeDeform也实现了实时非刚性重建,但不是开源的,其他相似的工作有Fusion4D。
Elastic Fusion:(RGB-D相机)一个实时稠密的视觉SLAM系统,能够捕获全面的、基于全局一致性的基于平面的房间尺度环境地图,使用RGB-D摄像机进行探索(Elasticfusion: Dense slam without a pose graph 2015)
InfiniTAM:(RGB-D相机)在Linux、IOS、Android平台运行的,具有CPU的实时三维重构系统(finiTAM v3: A Framework forLarge-Scale 3D Reconstruction with Loop Closure 2017 / Real-timelarge-scale dense 3d reconstruction with loop closure 2018)
Bundle Fusion:(RGB-D相机)支持鲁棒跟踪从严重跟踪故障中恢复,并实时重新估计3d模型,以确保全局一致性(Bundlefusion: Real-time globally consistent 3d re-construction using on-the-fly surface re-integration 2017)
KO-Fusion:(RGB-D相机)提出一种基于动态和里程计测量的轮式移动机器人的稠密RGB-D视觉SLAM系统(Ko-fusion: Dense visual slam with tightly-coupled kinematic and odo-metric tracking 2019)
SOFT-SLAM:(立体相机)(Soft-slam: Computationally efficient stereo visual slam for autonomousuavs 2017)得益于大范围的回环检测,系统可以创建稠密地图,基于SOFT进行位姿估计。(Stereo odometry based on careful featureselection and tracking. 2015)
5.2.4. 视觉惯性里程计SLAM
确定性在SLAM在技术上具有挑战性。单目视觉SLAM存在必要的初始化、尺度模糊和尺度漂移等问题(Scaledrift-awarelarge scale monocular slam 2010),虽然立体摄像机和RGB-D摄像机可以解决初始化和缩放的问题,但是有些障碍是不能忽视的,比如快速移动(可以用全局快门、鱼眼、全景相机等解决),以及小视场,大计算,遮挡,特征丢失,动态场景和变化的光线等问题。近年来,视觉惯性测程(VIO)SLAM技术成为研究热点。
首先(Keyframe-based visual–inertial odometry using non-linear optimization.2015 / Towards consis-tent visual-inertial navigation 2014 / igh-precision, consistentekf-based visual-inertial odometry 2013)在VIO方面进行了尝试。文献(Visual-inertial monocular slamwith map reuse.2017 / On-manifold preintegration for real-time visual–inertial odom-etry 2016 )在VIO进行了理论上的证明和推导。(Fast and robustinitialization for visual-inertial slam. 2019)使用几轮的视觉-惯性BA来为VIO进行稳健的初始化。特别的,tango(Aninvestigationof google tangoR©tablet for low cost 3d scanning 2017)、Dyson 360 Eye 以及 hololens ( Real-time high resolution 3ddata on the hololens. 2016)都是VIO类的真实产品,并且得到了较好的反馈。
除此以外,苹果的ARkit (filter-based) ,Google的ARcore (filter-based) 以及从内到外的uSens等都是VIO的技术。PennCOSYVIO(Penncosyvio: A challenging visual inertial odometry benchmark 2017)从一个VI传感器(立体相机和IMU)中进行数据同步,两个tang相关手持设备,以及三个GoProHero 4摄像头,内部校准,外部校准。
下面是一些开源的VIO系统(A benchmarkcomparisonof monocular visual-inertial odometry algorithms for flying robots) 2018:
SSF:(松耦合、基于滤波器)基于EKF的时间延迟补偿的单传感器和多传感器融合框架(Vision based navigation for micro helicopters 2012)
MSCKF:(紧耦合、基于滤波器)Google Tango产品所采用的,基于EKF滤波器(A multi-state con-straint kalman filter for vision-aided inertial navigation. 2007)。相似的工作有MSCKF-VIO,是开源的(Robuststereo visual inertial odometry for fast autonomous flight 2018)
ROVIO:(紧耦合、基于滤波器)基于使用跟踪全部3D路标点和图像块特征的EKF滤波器,支持单目相机。(Robust visual inertial odometry using a direct ekf-based approach. 2015)
OKVIS:(紧耦合、基于优化)一个开放的和经典的基于关键帧的视觉惯性SLAM,它支持单目和立体摄像机的滑动窗口估计。(Monocular visual-inertial state estimation for mobile augmented reality 2017)

VINS:VINS-Mono(紧耦合、基于优化方法)是一个实时的单目视觉-惯性SLAM框架,开源源码在Linux上运行,并与ROS完全集成。(Monocular visual-inertial state estimation for mobile augmented reality. 2017 / Online temporal calibration for monocularvisual-inertial systems.2018)VINS-Mobile是一个实时的单目视觉-惯性里程计VIO在IOS设备上运行。VINS-Fusion支持多个视觉-惯性(VI)传感器 (GPS, 单目相机 + IMU,立体相机 + IMU, 或甚至单个立体相机)它包括在线空间校准、在线时间校准和视觉回环检测。

ICE-BA:(紧耦合、基于优化方法)提出了一种增量式的、一致性的、高效的BA优化的视觉-惯性SLAM,在基于滑动窗口的小范围local的BA和在所有关键帧上的全局BA优化同时进行,实时的为每一帧输出相机位姿和更新地图上的点。(ice-ba: Incremental, consistent and efficient bundle adjustmentfor visual-inertial slam 2018)。
Maplab:(紧耦合、基于优化方法)一个开放的,面向研究的可视化惯性建图框架,用c++编写,用于创建,处理和多区域的地图。一方面,maplab可以被认为是一个现成的视觉惯性建图和定位系统,另一方面,maplab为研究社区提供了一套多区域建图工具,包括地图合并、视觉-惯性批处理优化、回环检测、3D稠密场景重建。(maplab: An open framework forresearch in visual-inertial mapping and localization 2018)

还有:VI-ORB(紧耦合、基于优化方法)是ORB-SLAM作者的另外的工作,但不是开源的。StructVIO、RKSLAM可以可靠地处理快速运动和强旋转的AR应用(Structvio: Visual-inertial odometry with structural regularity of man-made environments 2019 / Robust keyframe-basedmonocular slam for augmented reality.2018)。mi-VINS使用了多个IMU,用来应对IMU传感器失效的情况(Sensor-failure-resilient multi-imu visual-inertial navigation 2019)。其他工作还有(Continuous-time visual-inertial odometry for event cameras 2018 / Event-basedvisual inertial odometry.2017 / Event-based visual-inertial odometry on a fixed-wingunmanned aerial vehicle 2019)
另外,基于深度学习的VIO SLAM系统可以参见文献(Unsupervised deep visual-inertial odometry with onlineerror correction for rgb-d imagery. 2019)该方法提出了一个VIO的网络,而不需要IMU的内参以及IMU和相机的外部标定(外参)。文献(Visual-inertial odometry for unmanned aerial vehicle using deep learning 2019)提供了一个避免IMU和相机之间的标定的网络。
5.2.5. 基于深度学习的视觉SLAM
目前,深度学习在计算机视觉的维护中起着至关重要的作用,随着视觉SLAM的发展,越来越多的人将目光投向了深度学习。“语义SLAM”指包括了语义信息到SLAM过程处理,通过提供高层次的理解、健壮的性能、资源意识和任务驱动的感知来提高SLAM表现和表示。下面介绍带有语义信息的SLAM的实现:
- 特征和检测:
- Pop-up SLAM(单目)提出了一种实时单目平面SLAM的方法,证明了场景理解可以改善状态估计和稠密建图,特别是在低纹理环境中。平面测量来自应用于每张图像的三维平面模型。文献(6-dof object pose from semantickeypoints 2017)通过卷积神经网络获取了语义的关键点预测。
- LIFT可以比SIFT获取更多的稠密的特征点(Lift:Learned invariant feature transform 2016)。
- 在捕捉特征点的任务上,DeepSLAM有显著的性能差距表现(Towardgeometric deep slam. 2017)。
- SuperPoint提出了一种用于训练兴趣点检测器和描述符的自监督框架,该框架适用于计算机视觉中大量的多视图几何问题Su-perpoint: Self-supervised interest point detection and description 2018)。
- 文献(Stereo vision-based semantic3d object and ego-motion tracking for autonomous driving.2018)提出了使用易于标注的二维检测和离散视点分类,并结合轻量级语义推理方法来获得粗略的三维目标测量结果。
- GCN-SLAM提出了一个基于深度的网络GCNv2,用于生成关键点和描述符。
- 文献(Volumetric instance-aware semantic mapping and 3d object discovery 2019)融合了关于3D形状、位置、甚至是语义类别的信息。
- SalientDSO借助深度学习实现视觉显著性和环境感知。文献(Structure aware slam using quadrics and planes.2018)将检测到的目标作为二次模型集成到SLAM系统中。
- CubeSLAM(单目)一个3D物体检测和SLAM系统,基于立方体模型,实现了对象级别的建图、定位和动态对象跟踪。
- 文献(Monocular objectand plane slamin structured environments 2019)与基于特征点的SLAM相比,结合了cubeSLAM(高级对象)和Pop-up SLAM(平面地标)的系统使地图更密集、更紧凑、语义更有意义。
- MonoGRNet一个几何推理网络,用于单目3D目标检测和定位。其他的基于特征方法在事件相机的应用有文献(Fast event-based corner detection 2017 / Event-basedfeatures for robotic vision 2013)。
- 另外关于检测方面的深度学习综述,还有文献(Recent advances indeep learning for object detection 2019)
- 识别和分割:
- SLAM++(cad模型)介绍了一种新的面向对象的3D SLAM范式的主要优点,充分利用先验知识的循环,如许多场景由重复的、领域特定的对象和结构组成。
- 文献(Semi-dense 3d semantic mappingfrom monocular slam. 2016)结合了先进的深度学习方法和基于单目摄像机视频流的LSD-SLAM,二维语义信息通过具有空间一致性的连接关键帧之间的对应关系转移到三维映射中。
- Semanticfusion(RGBD)结合了CNN和先进的SLAM系统,ElasticFusion用来构建语义的3D地图。
- 文献(Meaningful maps with object-oriented semantic mapping. )采用了基于特征的RGB-DSLAM,基于图像的深度学习对象检测和3d无监督分割。
- MarrNet提出了一个端到端的可训练框架,顺序估计2.5D草图和3D物体形状。
- 3DMV(RGBD)结合RGB颜色和几何信息对RGB-D扫描进行三维语义分割。
- Pix3D研究三维形状建模从单一的图像。
- ScanComplete一种数据驱动的方法,以一个不完整的三维场景扫描作为输入,并预测一个完整的三维模型,以及每体素语义标签。
- Fusion++ 一个在线对象级的SLAM系统,它可以为任意的被测对象建立一个精确的三维图形映射。
- 当RGB-D摄像机浏览杂乱的室内场景时,Mask-RCNN的实例分割用于初始化紧凑的对象截断函数重建。
- SegMap基于3d片段的地图表示,允许机器人定位、环境重建和语义提取。
- 3D-SIS一种商用的RGB-D扫描三维语义实例分割的新型神经网络结构。
- DA-RNN采用一种新的递归神经网络结构对RGB-D视频进行语义标注。
- DenseFusion从RGB-D图像中估计一组已知对象的6d位姿的通用框架。
- 其他用于事件相机的可参考文献(An event-based classifier for dynamicvision sensor and synthetic data 2017 / Event-based gesture recog-nition with dynamic background suppression using smartphone com-putational capabilities. 2018 / Investigation of event-based mem-ory surfaces for high-speed detection, unsupervised feature extraction,and object recognition.2018)
- 尺度恢复:
- CNN-SLAM(单目)使用深度学习估计深度,其他工作还有DeepVO、GS3D。
- UnDeepVO基于深度学习,使用单目相机可以得到6自由度的姿势。
- 谷歌提出了文献(Learning the depths of moving peopleby watching frozen people.2019)提出了一种基于无监督学习的单目摄像机和人在场景中自由移动的稠密深度场景预测方法。
- 其他基于单目相机获取真实尺度的工作还有(Recovering stable scale inmonocular slam using object-supplemented bundle adjustment.2018)(Bayesian scale estimation formonocular slam based on generic object detection for correcting scaledrift.2017)。
- GeoNet一种用于从视频中估计单目深度、光流和帧间运动估计的联合无监督学习框架。
- CodeSLAM提出了一种从单张图片获取深度图的网络,该深度图可以与位姿变量一起有效地优化。
- Mono-stixels使用动态场景中的深度、动作和语义信息来估计深度???
- GANVO使用无监督学习框架,用来从无标签的图像中获取6D姿态估计和单目深度图,使用GAN网络。
- GEN-SLAM利用传统的几何网格和单目的拓扑约束输出稠密地图。
- 其他的还有DeepMVS、DeepV2D
- 姿态输出和优化:
- 文献(Learning visual odom-etry with a convolutional network 2015)是同步的立体的VO。
- 文献(Exploring representation learning with cnns for frame-to-frame ego-motion estimation 2015)利用CNN从光流中估计运动。
- PoseNet可以从单个RGB图像在没有优化的情况下得到6自由度的姿态估计。
- VInet(单目)首先实现对VIO中的运动进行估计,减少了对人工同步和校准的依赖。
- DeepVO(单目)提出了一种利用深度递归卷积神经网络(RCNNs)实现单目的端到端VO框架,类似的工作还有SFMlearner、SFM-Net。
- VSO提出了提出了一种新的视觉语义里程计(VSO)框架,利用语义实现对点的中期连续跟踪。
- MID-Fusion(RGBD,稠密点云)使用面向对象的跟踪方法估计每个存在的移动对象的姿态,将分割的MASK与现有模型关联起来,并逐步将相应的颜色、深度、语义和前景对象概率融合到每个对象模型中。
- 长时间定位:
- 文献(Probabilistic data association for semantic slam. 2017)提出了一个基于传感器状态和语义地标位置的优化问题,集成了度量信息、语义信息和数据关联。
- 文献(Lightweight unsupervised deep loopclosure.2018)提出了一种新颖的无监督的特征嵌入深度神经网络,该网络用于视觉的回环检测问题。
- 文献(Long-term visuallocalization using semantically segmented images 2018)提出的方法展示了语义信息比传统的描述符在长期视觉定位中更有效。
- X-View利用语义图描述符匹配进行全局定位,使得不同视点下的定位成为可能。
- 文献(Multimodal seman-tic slam with probabilistic data association. 2019)提出了一个解决方案,表示假设作为等效非高斯传感器模型的多模态,来预测目标类别标签和测量路标点的相关性。
- 动态SLAM:
- RDSLAM提出了一种能在动态环境下鲁棒工作的实时单目SLAM系统,基于新的在线关键帧表示以及更新的方法。
- DS-SLAM一个带有语义信息的SLAM系统,基于优化的ORB-SLAM,语义信息可以使得SLAM系统在动态环境下得到更好的鲁棒性。
- MaskFusion(RGBD,稠密点云)一个实时的、关注对象的、语义的、动态的RGB-D SLAM系统,基于Mask R-CNN,该系统对物体进行语义的标签,相似的工作还有Co-Fusion(RGBD)。
- Detect-SLAM将SLAM与基于深度神经网络的目标检测相结合,使这两种功能在未知动态环境中相互受益。
- DynaSLAM在静态地图的帮助下的一个单目立体、RGB-D相机SLAM系统,适用与动态环境。
- StaticFusion提出了一种动态环境下的鲁棒稠密RGB-D SLAM方法,该方法检测运动目标并同时对背景结构进行重建。
最近,还有一些工作利用深度学习来主导SLAM的整个过程,SimVODIS可以输出深度和帧之间的相对位姿,同时检测对象和分割对象边界框。
5.3. 挑战和未来
鲁棒性和可移植性
视觉SLAM仍然面临着光照条件、高动态环境、快速运动、强烈旋转和低纹理环境等重要障碍,首先,全局快门代替滚动快门是实现精确相机姿态估计的基础,像动态视觉传感器这样的事件相机每秒可以产生多达100万个事件,这对于高速和高动态范围的快速运动来说已经足够了。其次,使用语义特征,如边缘、平面、表面特征,甚至减少特征依赖,如跟踪接合边缘、直接跟踪或机器学习的组合可能成为更好的选择。三是基于SfM/SLAM的数学机制,最好使用精确的数学公式,使其性能更优。可以预见,SLAM的未来将是基于智能手机或无人机等嵌入式平台的,另一个方面就是3D场景重建,基于深度学习的场景理解。如何平衡实时性和准确性是一个重要的开放性问题,针对动态、非结构化、复杂、不确定和大规模环境的解决方案有待探索。(Simultaneous localization andmapping in the epoch of semantics: A survey. 2019)
多传感器融合
实际的机器人和硬件设备通常不只是携带一种传感器,通常是多种传感器的融合。例如,目前对手机VIO的研究将视觉信息和IMU信息结合起来,实现了两个传感器的互补优势,为SLAM的小型化和低成本提供了非常有效的解决方案。DeLS-3D是一个融合了摄像机视频、运动传感器(GPS/IMU)的传感器融合方案,以及一个3D的语义地图来达到系统的鲁棒性和效率。目前常用的有以下传感器,但不限于激光雷达,声纳,IMU,红外,相机,GPS,雷达等,传感器的选择取决于环境和所需的地图类型。
语义SLAM
事实上,人类识别物体的运动是基于感知,而不是图像的特征,在SLAM系统中,深度学习可以实现目标识别和分割,有助于SLAM系统更好地感知周围环境。语义SLAM对全局优化、回环检测以及重定位有一定的帮助。文献( A unifying view of geometry, semantics, and data associationin slam. 2018)提出:传统的SLAM系统依赖几何特征(如点、线——PL-SLAM、StructSLAM和平面来推断环境结构)。在大规模场景中,高精度实时定位的目标可以通过语义SLAM来实现。
硬件和软件
SLAM不是一个算法,而是一个集成的、复杂的技术。它不仅依赖于软件,而且还依赖于硬件,未来的SLAM系统将侧重于算法和传感器的深度结合。基于以上的说明,该领域的特定处理器而不是通用的处理器,集成的传感器模块而不是单独的传感器就像照相机将显示出巨大的潜力。
6. 激光和视觉SLAM系统
6.1. 多传感器标定
- 相机和IMU:
- Kalibr(kalibr: Calibrating the extrinsics ofmultiple imus and of individual axes.)是一个用来解决以下标定问题的工具箱:多相机标定、视觉-惯性传感器标定(相机-IMU)以及旋转快门相机标定。
- Vins-Fusion有在线空间校准和在线时间校准。
- MSCKF-VIO有相机和IMU传感器之间的校准。
- mc-VINS可以标定所有多相机和IMU之间的外参和时间偏移量。
- 另外,IMU-TK可以标定IMU的内参。
- 除此以外,文献(Selective sensor fusion forneural visual-inertial odometry 2019)提出了一个端到端的单目VIO网络,融合来自摄像头和IMU的数据。
- 相机和深度:
- BAD SLAM为这个任务提出一个使用同步全局快门、RGB和深度相机的计算基准。
- 相机之间:
- mcptam是一个使用多相机的SLAM系统,可以校准内部和外部参数。
- MultiCol-SLAM是一个多鱼眼相机的SLAM系统。此外,升级版的SVO也支持多相机。
- 激光雷达和IMU:
- LIO-mapping介绍了一种紧耦合的Lidar-IMU融合方法。
- Lidar-Align一种简单的方法来寻找三维激光雷达和6自由度姿态传感器之间的外参。
- 激光雷达的外部校准可参见(Extrinsic calibration of 2d laser rangefinders using an existingcuboid-shaped corridor as the reference 2018 / Extrinsiccalibration of 2d laser rangefinders based on a mobile sphere. 2018)
- 相机和激光雷达:
- 文献(Automatic onlinecalibration ofcameras and lasers. 2013)介绍了一种概率监测算法和一种连续校准优化器,实现了相机和激光雷达在线自动校准。
- Lidar-Camera初步试验利用3D-3D点对相关性寻找激光雷达和相机之间的精确的刚体变换(外参)。
- RegNet第一个利用(CNN)推导出多模态传感器之间的6个自由度的外参校准,并以激光雷达和单目摄像机为例进行了验证。
- LIMO提出一种从激光雷达测量中提取深度的算法,用于相机特征跟踪和运动估计。
- CalibNet一个自我监督的深度网络能够实时自动估计三维激光雷达和二维摄像机之间的6自由度刚体转换。
- Autoware是一个可以标定激光和相机光束的标定工具。
其他工作如SVIn2展示了融合声呐、视觉、IMU、深度传感器的水下SLAM系统,基于OKVIS。文献(nvironment driven under-water camera-imu calibration for monocular visual-inertial slam. 2019)提出了一种新的水下摄像机-IMU标定模型,文献(Improving underwater obstacle detection using semanticimage segmentation.2019)利用语义图像分割来检测水下障碍物。WiFi-SLAM演示了一种名为WiFi的新型无线信号SLAM技术。文献(Leveraging mmwave imaging and communications for simul-taneous localization and mapping 2019)使用毫米波来定位NLOS机器人。KO-Fusion融合视觉和轮式里程计,文献( Keyframe-based direct thermalinertial odometry 2019)在视觉退化的环境(如黑暗)中使用了热成像摄像机和IMU。
6.2. 激光雷达和视觉融合
- 硬件层:来自HESAI的Pandora是集成40线激光雷达的软硬件解决方案,5中彩色摄像机和识别算法。集成的解决方案可以使开发人员便于时间和空间上的同步问题。
- 数据层:激光雷达深度数据稀疏、精度高,而摄像机深度数据密集、精度低,这将可以实现基于图像的深度上采样。
- 文献(mage guided depth upsampling using anisotropictotal generalized variation.2013)提出了一种深度图上采样的方法。
- 文献(In defense of classicalimage processing: Fast depth completion on the cpu.2018)仅依靠基本的图像处理操作来完成激光雷达稀疏的深度数据补全。
- 在深度学习方面,
- 文献(Sparse-to-dense: Depth predictionfrom sparse depth samples and a single image2018)提出了使用一个深度回归网络直接从RGB-D原始数据中进行学习,并探讨了深度样本数量的影响。
- 文献(Sparsity invariant cnns. 2017)使用CNN对稀疏的输入进行操作,应用与对稀疏激光雷达扫描数据的深度数据补全。
- DFuseNet提出了一种基于从高分辨率图像中提取的上下文线索来对稀疏的范围测量进行上采样的CNN网络。
- LIC-Fusion融合IMU测量、稀疏视觉特征和提取激光雷达点。
- 任务层:
文献(Intersection safety using lidar and stereo vision sensors.2011)融合了立体相机和激光雷达进行感知。
文献(Multiple sensorfusion and classification for moving object detection and tracking.2015)融合了雷达、激光雷达和相机对运动物体进行检测和分类。
文献(Real-time depth enhancedmonocular odometry 2014)可以通过(RGB-D、和相机关联的激光雷达)的深度信息来增强VO,尽管这些信息是稀疏的。
V-Loam提出了一种结合视觉里程计和激光里程计的通用融合框架。在线的方法从视觉里程计和基于激光里程计的扫描匹配开始,同时运动估计和点云配准。
VI-SLAM考虑了结合精确激光里程计并使用视觉的环境识别进行回环检测。( Visual-LiDAR SLAM with loop closure.2018)
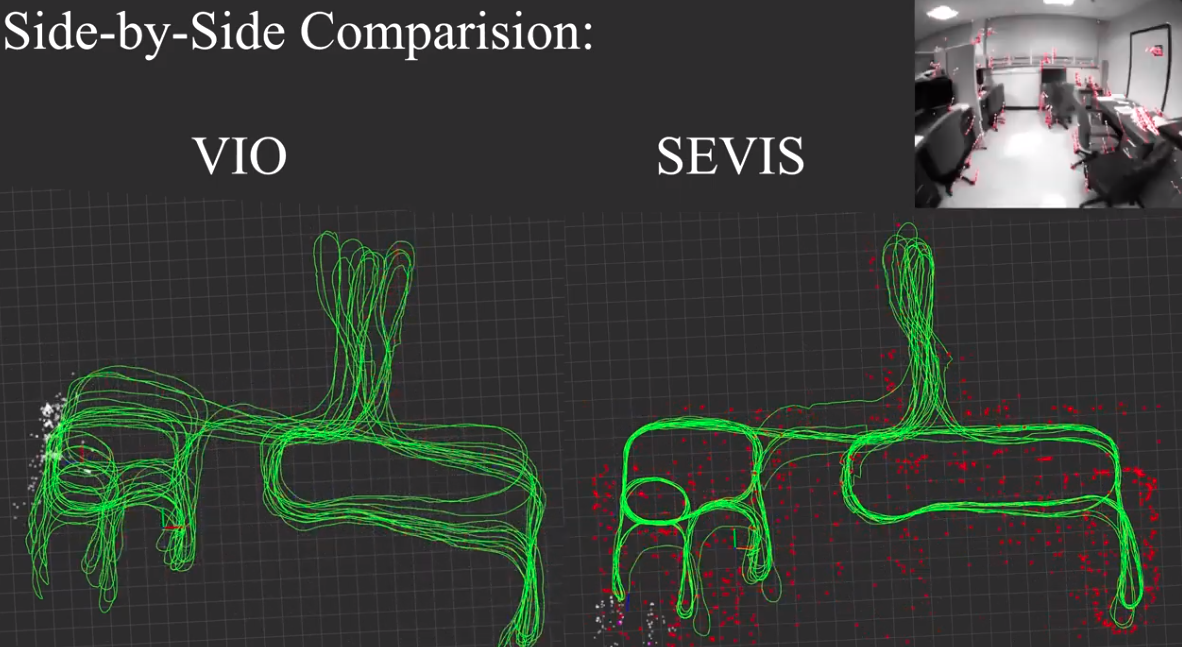
文献(Slam of robot based onthe fusion of vision and lidar.2018)目的是在SLAM的跟踪部分使用RGB-D相机和2D低成本激光雷达来完成鲁棒性的室内SLAM,基于模式转换和数据融合。
VIL-SLAM对(紧耦合的VIO)与激光雷达建图进行组合,并利用激光雷达提高视觉上的回环检测(Stereo visual inertial lidar simultaneous localization and mapping 2019)。
文献(Lidar-aided cam-era feature tracking and visual slam for spacecraft low-orbit navigationand planetary landing. 2015)结合了单目相机图片和激光距离测量使视觉SLAM系统消除尺度不确定性带来的误差。
在深度学习方面,许多方法来检测和识别融合的来自摄像机和激光雷达数据,如PointFusion、RoarNet、AVOD、MV3D、FuseNet。此外,文献(Deepcontinuous fusion for multi-sensor 3d object detection. 2018)利用端到端的学习架构以激光雷达和相机数据输入,获得了十分精确的定位性能表现。
6.3. 挑战和未来
- 数据关联:未来的SLAM必须集成多传感器,但是不同的传感器具有不同的数据类型、时间戳和坐标系统表达式,需要统一处理。此外,还需要考虑多传感器之间的物理模型建立、状态估计和优化问题。
- 硬件整合:目前,尚无合适的芯片和集成硬件使SLAM技术更容易成为产品。另一方面,如果传感器的准确性由于故障而下降,非正常条件,或老化,传感器测量的质量(如噪音、偏差)与噪声模型不匹配,那么鲁棒性和硬件的整合也要跟随。前端传感器应具备数据处理能力,从硬件层向算法层演进,再由功能层向软件开发工具包(SDK)进行应用。
- 协同:分散的视觉SLAM对于多机器人在绝对位置系统不可用的环境下十分有用。协同优化视觉多机器人SLAM需要分散数据和优化,这被称为协同。
- 高精地图:高清晰度地图对机器人(无人车)来说是至关重要的,但是哪种地图最适合机器人呢,密集地图或稀疏地图可以进行导航、定位和路径规划吗?一个相关的开放问题是长期建图需要多久更新一次地图上的信息,以及如何决定哪些信息是过时的需要被去除的。
- 适应性、鲁棒性、可伸缩性:当前还没有一个SLAM系统可以覆盖所有的场景。为了在给定的场景中正确工作,大多数都需要大量的参数调优。为了让机器人像人类一样感知,我们倾向于使用基于外观的方法,而不是基于特征的方法,这将有助于在白天和夜晚之间或不同季节之间形成语义信息的循环。
- 抗风险和约束的能力:完美的系统应该是故障安全的和故障感知的,这里不是关于重定位或者回环检测的问题。SLAM系统必须具备对风险或失败做出反应的能力,同时,一个理想的SLAM解决方案应该能够在不同的平台上运行,而不受到平台算力条件的限制。如何平衡准确性、鲁棒性和有限的资源是一个挑战性的问题。
- 应用:SLAM技术有着广泛的应用如:大范围的位置、导航、3D和语义地图的重建,环境识别和理解,地面机器人,无人机,VR、AR、MR、AGV,自动驾驶,虚拟装潢,虚拟室内拟合,沉浸式游戏,抗震救灾等。
- 开放问题:端到端学习会攻占SLAM吗?