Automatic Extrinsic Calibration Method for LiDAR and Camera Sensor Setups

摘要
本文提出了一种无需用户干预即可进行激光雷达-立体相机对的外在校准的方法。我们的校准方法旨在解决汽车设置中常见的限制,例如低分辨率和特定的传感器姿态。
介绍
现有的校准方法要么需要复杂的设置,要么缺乏通用性,因此结果的准确性在很大程度上取决于传感器的参数或环境的结构性。
与现有方法不同,没有进行严格的假设,因此允许中等分辨率如16线lidar,以及适用于传感器之间的相对姿势较大的情况。
我们的方法可以使用简单的设置在合理的时间内执行,该设置旨在利用来自两个设备的数据中的对应关系。
标定
一个定制的平面target用于提供两个传感器之间的特征配对关系,如图2所示

图2所示的模式具有几何和视觉特性,可以估计lidar、双目、单目的关键点。一方面,4个圆孔可以利用激光、双目点云的不连续性获取,另一方面,4个ArUco标记放置于4个角点附近,可以使用单目摄像头获取。
这种方法不会对传感器之间的相对姿态有较强的限制,因此适用于平移和旋转较大的情况。实际上,只需要满足两个约束即可:
- 传感器之间必须有包含校准目标的共视区域
- 传感器可以良好的观察到校准目标(如圆孔),特别的,当校准中包含距离数据时,每一个圆至少需要3个点来表示。对于多线激光雷达而言,必须要有两根线达到同一个圆上
- 特别的,对于视觉传感器而言,需要提前知道设备内参
提出的方法如图3所示,分为两个阶段:
- 第一阶段包括校准目标的分割和每个传感器的参考点定位
- 第二阶段是求解参考点的转换
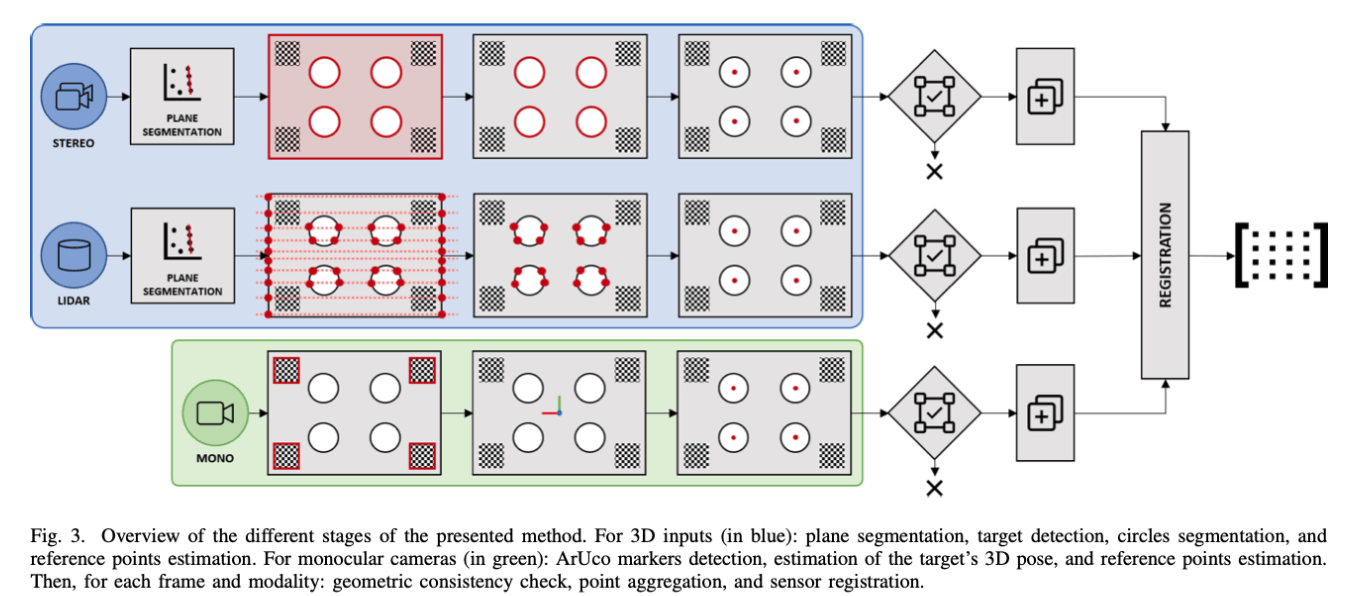
目标分割
这第一阶段旨在在每个传感器的数据中对校准目标进行定位,在此阶段中的信息是相对于该传感器坐标系而言的。最终输出一组包含4个3D点数据,
激光雷达数据
在将数据馈送到分割处理之前,通过了三个笛卡尔坐标的pass-through滤波器来提出无关数据的影响,因此必须根据传感器重叠区域的位置和大小来设置pass-through滤波器的限制。
预处理后的点云\(\mathcal{P}_{1}^{L}\)包含校准目标和激通过孔中可见的点。对于\(\mathcal{P}_{1}^{L}\)中的每一个点,按下式计算其深度梯度幅值:
\[ p_{i, \Delta}=\max \left(p_{i-1, r}-p_{i, r}, p_{i+1, r}-p_{i, r}, 0\right) \]
其中,
- \(p_{i,r}\)表示关于点\(p_i\)的测量
- \(p_{i-1},p_{i+1}\)是点\(p_i\)的同一线束扫描的邻近点
然后,利用一个阈值对所有不连续性较高的点进行提取,得到点云\(\mathcal{P}_{2}^{L}\)
双目/立体摄像头数据
当要校准的传感器之一是立体视觉系统时,首先通过立体声匹配过程将原始图像对转换为3D点云。
在我们的实验中,我们使用OpenCV实现的[28]的半全局块匹配(SGBM)变体,我们发现我们发现合理准确地进行深度估计。注意,当涉及这种模态时,预计校准目标将具有一些纹理(例如,木纹),以便可以成功解决立体声对应问题。但是,在我们的实验中,我们发现由模式边界引起的强度差异通常是足够的,。
与激光雷达数据处理类似,首先通过pass-through滤波器进行过滤。不同的是,对于立体视觉,通过提取点云目标的边缘,具体地,使用sobel算子来对图像提取边缘,然后根据边缘强度对点云进行滤除,得到点云\(\mathcal{P}_{2}^{S}\)
对深度数据提取目标点
这一步主要是对激光雷达/立体视觉预处理后的数据进行下一步处理:
(1)平面分割:
首先,使用RANSAC算法对点云\(\mathcal{P}_{1}\)(包括激光雷达/立体视觉)进行平面拟合得到模型\(\pi\),为了确保模型的准确,使用了较为严格的RANSAC阈值,并且提取的平面必须大概与传感器坐标系成垂直关系,使用一个容限\(\alpha_{plane}\).
然后,根据得到的平面模型\(\pi\),对点云\(\mathcal{P}_{2}\)中的点进行剔除,然后得到点云\(\mathcal{P}_{3}\)
(2)转换到2d空间:
由于所有其余点都属于同一平面,因此在该点执行降维:通过转换x-y平面与模型\(\pi\)重合,可以将点云\(\mathcal{P}_{3}\)转换到平面点\(\mathcal{P}_{4}\)
(3)圆形提取
接下来,使用2D圆分割来提取\(\mathcal{P}_{4}\)中存在的图案孔的模型,此步骤是迭代地执行的过程中,在寻找最可能的圆圈,并且在寻找下一个圆之前,剔除掉已经找到的圆。如果找到4个圆,才进入下一步。
为此,将中心分成四个一组,并将它们形成的矩形的尺寸(对角线,高度,宽度和周长)与理论值进行比较,公差δ一致性表示为与中心线的偏差百分比。 期望值。 大概只有一组中心可以满足这些限制,
一旦识别到圆,就可以将其圆心反投影回3d空间,形成点云\(\mathcal{P}_{p}\),\(\mathcal{P}_{p}\)必须正好是4个中心点。
单目摄像头数据
如果要校准的传感器是单眼相机,则参考点的提取需要检测ARUCO标记,其提供所需的提示来检索目标的几何形状。Aruco标记是由黑色边界和内部二进制矩阵制成的合成方标记,旨在允许其明确识别[27]。 在我们的校准目标中,使用四个ARUCO标记,每个角落都是一个; 由于此位置,它们不会影响其他方式的目标或孔检测。
如果相机内参以及标记的尺寸已知,就可以通过Pnp恢复每个标记相对于相机坐标系的位姿,在我们的实施中,我们将四个标记设置为一个ARUCO板,这个板允许利用4个标记来共同估计校准目标的位姿。
然后通过LM优化来最小化重投影误差来求解ARUCO板的位姿,使用4个标记的位姿均值作为初始值,最后得到了ARUCO板中心的3d位姿。
为了生成与点云\(\mathcal{P}_{p}\)同等的4个点,利用已知的相对位置关系来分别提取4个圆孔中心的3D点,得到点云\(\mathcal{P}_{M}\)
点云聚类
在分割阶段的最后,已经得到了两组点云\(\mathcal{P}_{p}\),每一组点云都是相对于传感器坐标系的。
这些数据足以找到转换传感器的相对姿势的转换,然而,方法固有的不同噪声源(例如,传感器噪声和诸如Ransac等非确定性程序)可能会影响结果的准确性。为了提高算法的稳健性,我们通过反复应用分割步骤并以两种不同的方式累积结果来增加可用的信息
(1)数据帧累积
由于场景可以是静止的,因此可以通过累积N帧的点云\(\mathcal{P}_{p}\)来得到\(\mathcal{P}_{p}^{'}\),如果找到的超过4个圆,则不可用
(2)目标板不同位姿的数据累积
本方法可以通过单个目标板的位姿来求解,然而,通过考虑超过四个参考点,可以提高估计的准确性。另一方面,单帧提取得到的4个点有可能不共面,通过多帧可以提高标定效果。
配准
在分割阶段结束后,一共获取到两组\(\mathcal{P}_{p}^{'}\)点云,每组分别对应一个传感器,主要包含每个圆圈中心相对于该传感器坐标系的点。并且,两组点云的点对关系是已知的。
点关联
提出了一种策略,来避免设置两组\(\mathcal{P}_{p}^{'}\)点云的点具有相同的顺序关系。
首先将\(\mathcal{P}_{p}^{'}\)点云中的4个点投影到球面坐标系,然后(only assume that the point that appears highest in the cloud, that is, the one with the lowest inclination angle, belongs to the upper row of the calibration target (i.e., either the top-left or the top-right circle).)
上面步骤首先确定了一个上方的点,然后根据这一点到另外三个的距离确定了正确的排序。因此,可以建立起关联:

求解
排序好的两组点云,记为\(\mathcal{P}_{c}^{'X},\mathcal{P}_{c}^{'Y}\),通过使用Umeyama配准[30],可以寻找两组点云的刚体变换,其中,两组点云中的点具有匹配关系如下:
\[ p_{i, a}^{X}=p_{i, a}^{Y} \wedge p_{i, m}^{X}=p_{i, m}^{Y} \]
即目标函数为两组点云之间的距离:
\[ \frac{1}{4 \cdot M} \sum_{i=0}^{4 \cdot M}\left\|\mathbf{p}_{i}^{X}-\mathbf{T}_{X Y} \mathbf{p}_{i}^{Y}\right\|^{2} \]
由于点云配对关系已知,所以使用svd即可求得闭式解。方便的是,Umeyama方法可以处理所有点都在同一平面上的情况,例如使用单个图案位置(M = 1)时,这样可以避免将它们误认为是反射。
实验
除了需要人工放置标记板之外,其他参数使用固定值如下表:
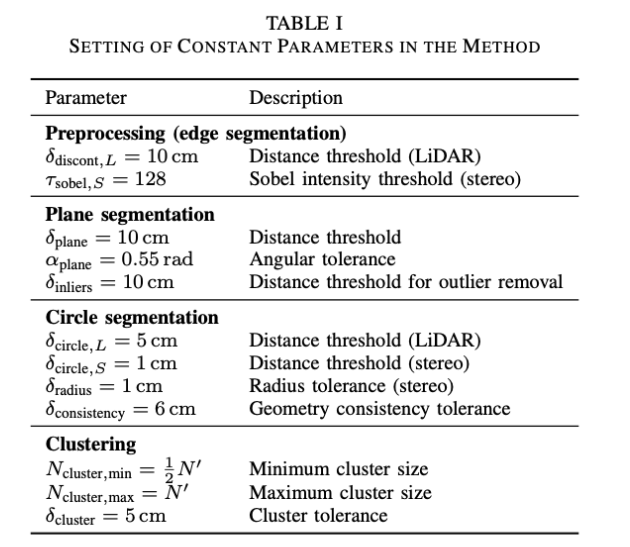
其中,除非另有说明,否则参考点累积超过30帧(n = 30)
gazebo仿真
在实验中,将目标放置在后面的墙壁,使得穿过圆孔的LIDAR梁到达表面,在前景和背景点之间产生必要的梯度。
高斯噪声\(\epsilon \sim \mathcal{N}(0,(K\sigma_{0})^{2})\)被施加到传感器的捕获数据,对于像素强度和激光距离,\(\sigma_{0}= 0.007\) m和\(\sigma_{0}= 0.008\)米,其中:
- K=0表示理想环境
- K=1表示真实环境
- K=2表示噪声环境
特征提取实验
实际上,该方法无法在一些极端配置中提供结果; 具体为在LIDAR扫描仪的情况下,它们有限的分辨率使得不可能在远距离找到圆圈,而立体声受到深度估计的实质性降级的影响,即这种模块遭受的距离增加。
因此,在典型用例中,应该通过将图案位置限制为相对于传感器的合理距离范围来避免这些情况
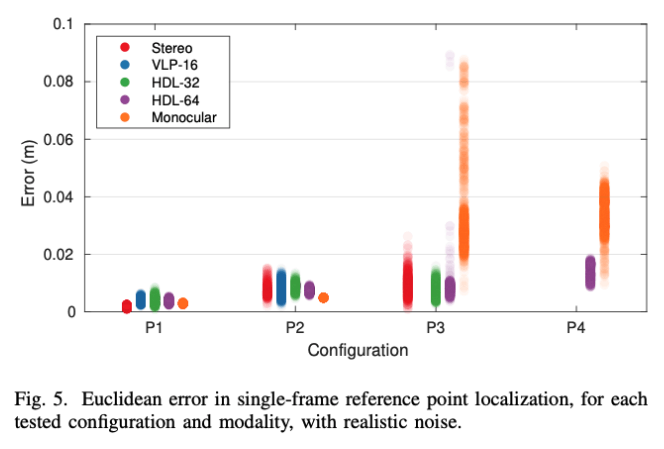
求解结果
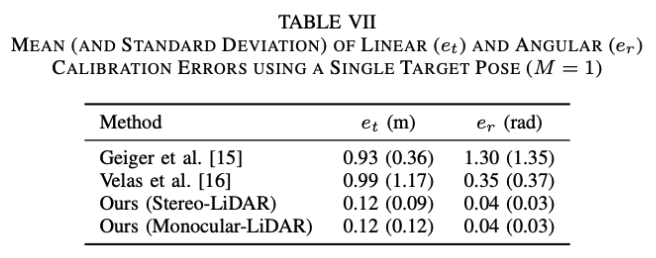
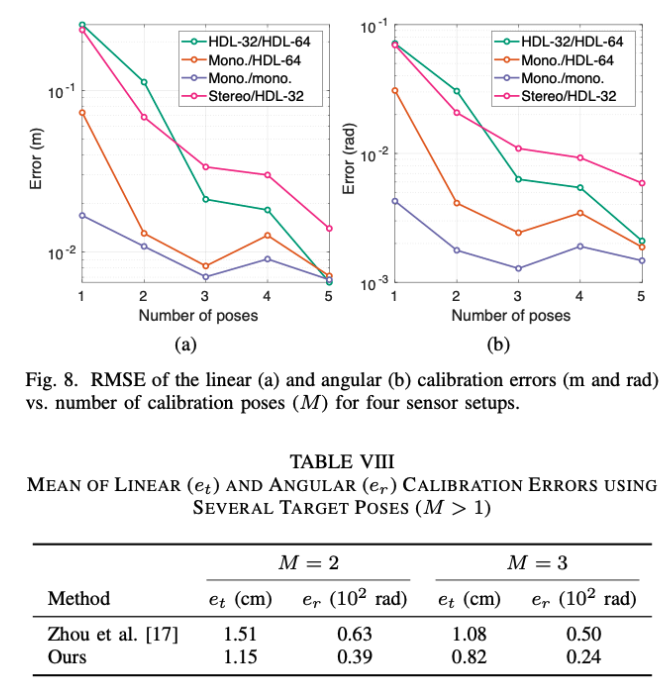
真实环境实验
