1. D3VO: Deep Depth, Deep Pose and Deep Uncertaintyfor Monocular Visual Odometry
2. 摘要
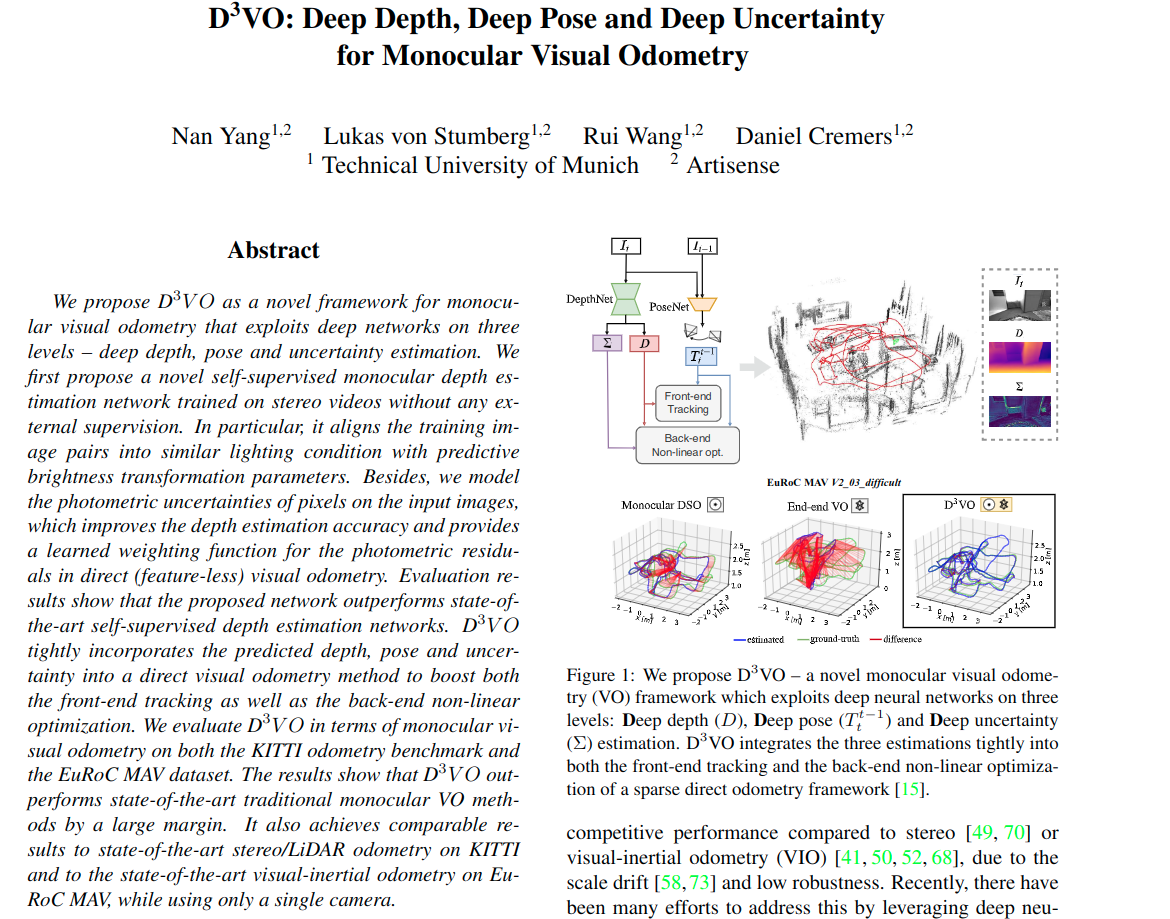
3. 方法
首先提出一种自监督网络,用来预测深度、位姿、和不确定性,网络同时估计仿射亮度变换参数来对齐训练图片的光照度,在这个自监督框架里面。光度不确定度是根据每个像素可能的亮度值的分布来预测的。因此提出这个D3VO作为直接的VO框架,将预测到的特性分别包含在前端跟踪和后端BA优化中。
3.1. 自监督网络
提出的单目深度估计网络的核心是对视频序列进行使用\(DepthNet\)来学习深度,并同时使用\(PoseNet\)学习运动 (文献24,81)。这种自监督训练是通过最小化当前图像和静态立体图像之间的光度重投影误差来实现的
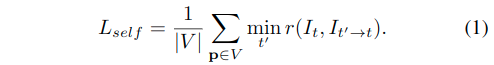
其中,\(V\)是在图片\(I_t\)上的所有像素集合,\(t'\)表示所有图像帧中的索引idx。在作者的设置中,\(I_t\)是左侧Image,\(I_{t'}\)包含了它的两个相邻的两个时间Frame和它的对位(右)的Frame,(如\(I_{t'}\in \{ I_{t-1},I_{t+1},I_{t^s} \}\))。每个像素的最小化loss使用文献24提出的\(Monodepth2\),这是为了解决不同源Frame之间的遮挡问题。
为了简化表示,使用\(I\)来取代\(I(p)\),\(I_{t' \rightarrow t}\)表示使用预测的深度\(D_t\)对双目立体相机图像进行变换,以及相机的位姿\(T_{t}^{t'}\),相机的内参\(K\),以及可微分的双线性采样器(文献30)来合成,[说白了就是重投影?].
注意到对于从右目相机到左目相机的\(I_{t^s \rightarrow t}\),相机位姿变换\(T_{t}^{t'}\)是已知的、固定的。\(DepthNet\)同时预测右目图像\(I_{t^s}\)的深度图\(D_{t^s}\),通过向网络输入左侧图像\(I_t\)的方式,文献25提出的。
训练\(D_t\)需要通过生成\(I_{t\rightarrow t^s}\)(即输入左目图像,生成右目深度图),然后与\(I_{t^s}\)(实际的右目的深度图)做比较。
为了简化,下面只讨论左侧图像的loss,通用的光度误差公式为:
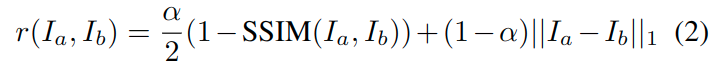
这是基于光度不变性的假设。然而,由于相机的光照变化和自动曝光,L1和SSIM[文献72]都不是固定不变的,可能会违反这一原则。因此,我们提出了明确的使用预测的亮度转换参数对摄像机曝光变化进行建模。
3.1.1. 亮度转换参数
相机曝光调整引起的图像强度变化可以用2个参数的仿射变换来表示

尽管它很简单,这个公式在直接法SLAM中表现出十分有效,在[文献15,17,31,70]提到的。受这些工作的启发,作者提出了预测变形参数的方法,即根据参数来将左侧图像\(I_t\)的光度条件与\(I_{t'}\)对齐,于是可以将等式1进行重写:
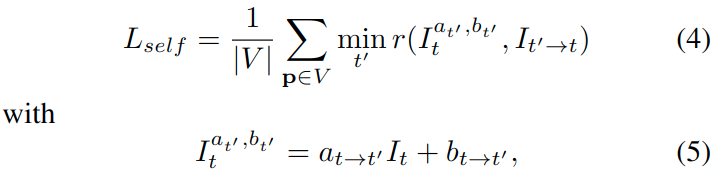
其中,\(a_{t\rightarrow t'}\)和\(b_{t\rightarrow t'}\)是将左侧图像\(I_t\)对齐到\(I_{t'}\)的参数。注意,这两个参数都可以在没有任何监督信号的情况下以自我监督的方式进行训练。下图展示了变换的结果:

3.1.2. 光度不确定性
仅建模亮度变化参数不足以应对光度不变性假设的所有失效情况,其他情况,如非朗伯曲面和运动物体,是由相应物体的固有性质引起的,这些性质对于分析建模来说有一定影响。由于这些方面可以看作是观测噪声,我们(leverage)利用Kendall等人提出的深度神经网络的异方差任意不确定性概念[文献33],其主要的思想是基于ground-true label y来预测每个像素的后验概率分布(使用它的均值和方差\(p(y|\tilde{y},\sigma)\)),例如,通过假设噪音是拉普拉斯的,该分布的负对数似然函数可以写成:
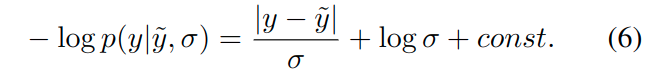
注意,对于方差\(\sigma\)并不需要真实的标签label来训练。预测不确定性允许网络根据数据输入调整残差的权重,这样有利于提高模型对噪声数据或错误标签的鲁棒性[文献33]。
在这个例子中,真实标签y就是目标图像的像素强度。对于左侧图像\(I_t\)上的哪些可能违反光度不变性的像素区域而言,网络将会预测更高的\(\sigma\),类似与[文献38],通过对等式4进行变换来实现:
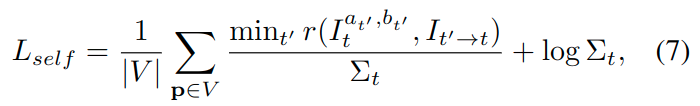
其中,\(\Sigma_t\)是左侧图像\(I_t\)的不确定性map(映射?图?)。下图4分别展示了在KITTI和EuRoC数据集上预测不确定性map的结果。接下来,将展示证明学习\(\Sigma_t\)对光度残差进行加权对于D3VO的有效作用。

4. D3VO
上面讲了自监督网络来预测深度图\(D\),不确定性图\(\Sigma\)和相对位姿\(T_{t}^{t'}\)。接下来,是关于D3VO如何将这些预测整合到一个滑动窗口的稀疏(光度重投影)BA调整公式中,如[文献15]提及的。
接下来的讨论将使用\(~\tilde{\cdot}~\)来表示从网络中得到的预测值,如\(\tilde{D},\tilde{\Sigma},\tilde{T_t^{t'}}\),来避免歧义。
4.1. 光度能量
像其他直接法如[文献15,16,18],D3VO旨在最小化总的光度误差\(E_{photo}\)如下:

其中,\(\mathcal{F}\)是关键帧的集合,\(\mathcal{P}_i\)是第i个关键帧的点集(注意,不是一个点),\(obs(\boldsymbol{p})\)是能够观测到点\(\boldsymbol{p}\)的关键帧集合。\(E_{\boldsymbol{p}j}\)是将\(\boldsymbol{p}\)点投影到关键帧\(j\)时的加权光度:
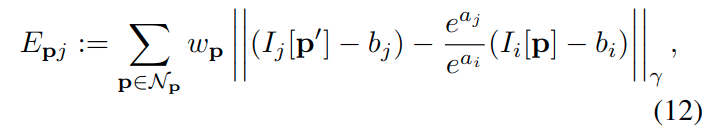
上式中,\(\mathcal{N}\)是点\(\boldsymbol{p}\)的8个邻近像素集合[文献15],\(a,b\)是光度变换参数,\(||\cdot||_{\gamma}\)是Huber核函数规范化,在[文献15]中,残差的权重定义为:
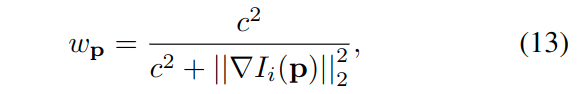
意义是降权像素具有高的图像梯度来补偿小的独立几何噪声。在现实的情况下,有更多的噪声源,例如,反射,这需要被建模用于精确和鲁棒的运动估计。于是,作者提出了使用学习的不确定性\(\tilde{\Sigma}\)来表示权重函数:
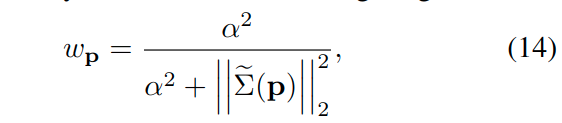
这可能不仅仅是依赖局部图像的梯度,有可能是更高级别的噪声模式(higher level noise pattern)。如上图4中,对于车辆的窗户,移动的物体如骑自行车的人,在深度不连续的地方如物体边界,网络都能预测出较高的不确定性。
投影点\(p'\)的位置由下式给定:
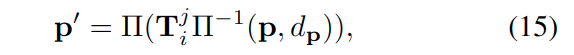
其中,\(d_p\)是点\(\boldsymbol{p}\)在第i个关键帧的相机坐标系的深度,\(\Pi(\cdot)\)是利用已知相机内参进行投影,这里定义\(\Pi(\cdot)\)来获得齐次坐标。相比于传统直接法[文献15,16]中使用随机初始化深度\(d_p\),作者提出使用估计的深度\(d_p=\tilde{D}_i[\boldsymbol{p}]\),可以提供(metric scale)衡量尺度的?
受[文献78]启发,作者提出对等式11的立体相机版本:
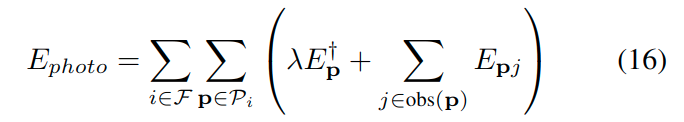
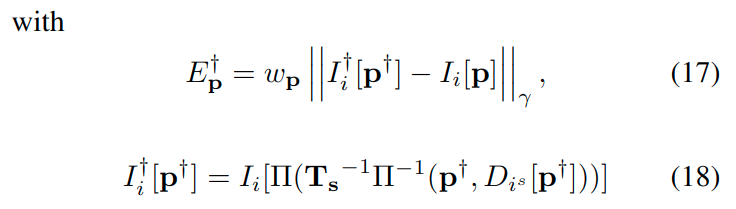
其中,\(\boldsymbol{T_s}\)是从左侧图像到右侧图像的变换矩阵,其中应用了训练得到的\(DepthNet\)和下式:
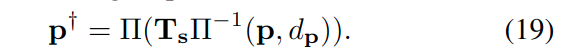
虚拟立体项优化了估计的来自VO系统中的深度\(d_p\),使其与所提出的深度网络预测的深度一致。
姿态能量
不像传统的直接法VO一样,使用恒速度模型来为新的一帧初始化前端跟踪,作者提出了使用连续帧之间的姿态预测值来初始化前端,而不是初始化直接图像对齐。这个来自跟踪前端的位姿估计将用于初始化后端BA优化。利用所预测的关键帧姿态\(\tilde{T}_{i-1}^{i}\),进一步介绍相对关键帧姿态\(T_{i-1}^{i}\)的先验。
即\(\tilde{T}_{i-1}^{i}\)通过连接第i-1和第i帧之间所有帧间位姿预测值计算得到。
于是,姿态能量可以表示为:
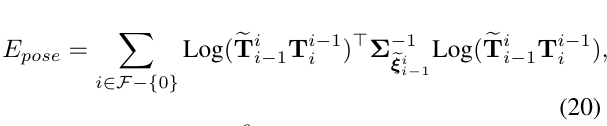
其中,\(Log:SE(3)\rightarrow \R^6\) 表示将李群中的SE3变换矩阵映射到它的李代数形式,\(\xi \in \R^6\),即变成6维向量。另外,对角逆协方差矩阵\(\Sigma_{\tilde{\xi}_{i-1}^i}^{-1}\),可以通过在连续的帧匹配对传播协方差矩阵得到,被建模为常数对角矩阵。
总的能量函数可以写成:
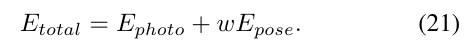
将式21中的位姿先验项\(E_{pose}\)考虑在内,可以类比于用高斯噪声模型将MU预积分位姿先验集成到系统中
\(E_{total}\)使用高斯牛顿法来进行优化。
总结: 介绍了将预测的位姿作为前端跟踪和后端优化初始值,并且将它们进行正则化到光度BA优化的能量函数中的思路。