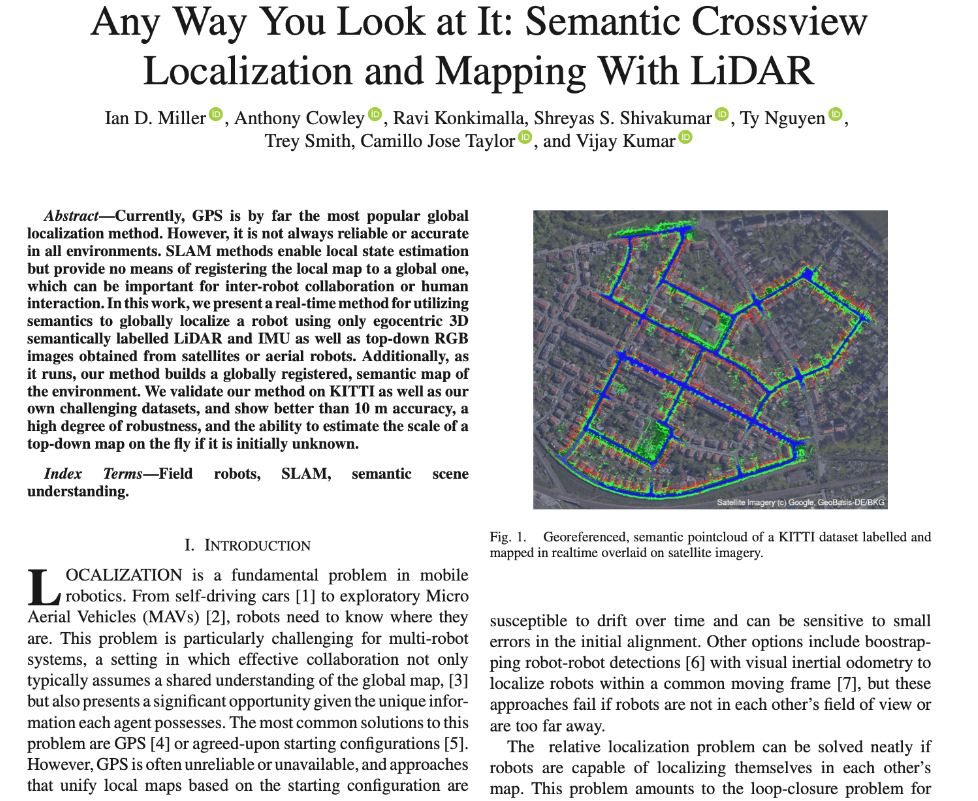
Any Way You Look at It: Semantic Crossview Localization and Mapping With LiDAR
摘要
GPS是迄今为止最受欢迎的全球本地化方法。 但是,在所有环境中,它并不总是可靠或准确。 SLAM方法使能局部估计能够提供将本地地图注册到全局的局部估计,这对于机器人间协作或人类互动可能是重要的。
在这项工作中,提出了一种利用语义的实时方法,仅使用以自我为中心的 3D 语义标记的 LiDAR 和 IMU 以及从卫星或空中机器人获得的自上而下的 RGB 图像来全局定位机器人。
介绍
提出一种将地面机器人的局部观测信息与来自卫星或无人机的大范围全局地图进行匹配的定位方法,这种方法比传统的基于已知地图定位方法更加具有挑战性,因为对于大多数机器人而言,the overhead views 与 以自我为中心的观测数据有较大不同。因此,在鸟瞰图中直接应用基于特征的配准方法对机器人进行定位通常是无效的。此外,卫星图通常在不同的时间拍摄,这意味着配准方法必须适应季节的变化。
近年来,使用人工神经网络(ANNS)的图像语义分割已成为成熟的技术。地图语义对于cross-view registration是理想的,因为在足够多样化的训练数据中,可提取具有视角和季节不变性的语义信息。此外,从鸟瞰图中提取粗略的语义信息比从the overhead views 中提取更加简单,无论是手工提取还是基于ANN的方法。
与此同时,Lidars在光束密度增加同事,价格和重量下降,因此将它们放在小型移动机器人上现在是实用的。同时应用两种传感技术将可以产生稠密的语义点云。
最近的工作使用了用于cross-view定位的图像语义信息[15],[16],但通常没有只有很少的利用了深度信息或环境的有力的结构假设。如基于几何方法如 [3] 通常在没有足够几何结构的环境中失效,相反,我们引入了一种结合这两种信息来源的方法,以实现更强大的语义cross-view定位系统。
主要贡献如下:
- 提出一种实时的
cross-view定位和建图框架,如果鸟瞰地图未知但有界,我们的方法也能够估计它的比例。 - 我们使用Semantickitti [17]以及我们自己的数据集以及在包括农村和城市环境的各个地点,验证我们所提出的方法。
- 开源了代码
相关工作
图像匹配
Cross-view localization问题定义为图像匹配问题[12]:给定一个由图片构成的数据库作为全局地图,以及一张待查询的图片作为局部观测。问题可描述为该问题通过获取一些描述符,使得来自多个视图的相同位置的图像在一些潜在的空间中接近。
早期的工作如[18],[19],使用局部特征描述符。 Majdik等[11]使用来自Google Street View的图像特征来与四旋翼无人机飞行拍摄图来进行匹配。然而,这些方法往往在极端视角的情况下失效。
这个限制导致了最近兴起的使用孪生神经网络[20], [21]方向,这些网络通过对不同视点的图像使用权重共享的分支网络结构在潜在空间进行交叉关联,来决定两个图像的相似度。整个网络在已知的图像对上训练,在线处理图像对时,这些网络相对较慢,因此不能在机器人应用程序中实时运行,其中必须同时查询许多可能的状态。
基于视觉
图像匹配算法提供了一种将图像与提供的现有图像数据库进行比较的方法,但它们并未明确寻求估计机器人或传感器的位置。定位需要具有pose label或整个航拍地图的图像数据库,如[22]中的描述。在这项工作中,作者使用鸟瞰坐标系中的一系列边缘来代表全局地图,然后在粒子滤波框架中与地面图像进行边缘匹配。但是,通过将全局地图减少为一系列边缘,将会丢弃大量的有用信息。
其他工作如[23],使用立体图像来生成RGBD图像,然后将它从鸟瞰角度进行渲染生成,然后使用chamfer matching与已知地图进行匹配,尽管如此,这种方法未能解决由季节变化或环境中的动态物体(如人或汽车)等因素引起的摄影变化。
为了更好地应对季节性变化和更加极端的观点变化,最近的工作越来越多地分析了语义的定位使用。Castaldo等 [15]对地面图像分割,并使用homography和地平面将语义特征投影到自上而下的视角。然后开发出一种针对分割图像的语义描述符,并与已知地图进行比较,以在相机位置集合生成对应的热图(heatmap)。然而,改方法并没有利用时间或深度信息,导致大规模定位系统的收敛速度较慢。另外,他们的方法在homography不成立的情况下失效,如路面并非平坦的工况。
类似的工作还有Gawel et al. [16],为空中图和地面视图生成语意图表示,然后构建描述符以匹配各种合成数据集。
基于激光雷达
Wolcott等人 [24]通过从各种透视图渲染一个已知的高分辨率点云并最大化互相关信息来对相机进行定位。Gawel等人 [3]通过从两个角度构建点云地图并使用几何描述符匹配它们来交叉定位地面和空中机器人。Barsan等人 [25]使用孪生网络实现厘米级定位。虽然上述方法准确和强大,这些方法需要相关环境的预先存在点云图,而我们只需要单个航拍图像。
与基于视觉的方法一样,最先进的基于Lidar的方法利用环境的语义结构。在早期的工作中,Matei等人[26] 从无人机采集的点云来拟合一个最接近的建筑模型,用于创建与地面图像相比的地面预测。
……
与这些工作相比,我们的框架只需要一个卫星或环境的鸟瞰图,这适合更多的应用。
具体方法
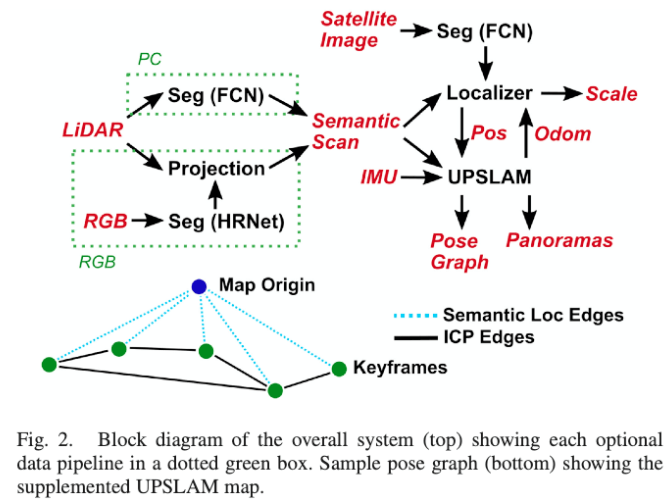
我们的方法由两个主要组件组成:基于ICP的LIDAR SLAM系统 - Panoramas Slam [32](Upslam) - 以及基于粒子滤波器的语义定位器,如图2所示
定位
粒子滤波器特别擅长处理多模态分布,这在机器人定位问题中经常出现,这将带来计算量的问题,我们通过使用优化策略来减少计算成本:
问题描述
对于2D地图的定位,我们系统状态\(x\)由tuple(\(p\in SE(2) , s \in [S_{min},S_{max}]\))构成,其中,\(p\)表示机器人位姿,\(s\)表示地图尺度(px/m)。我们还有控制输入量\(u\in SE(3)\),从上一帧到当前帧的相对位姿变换,该值来源于UPSLAM或者其他里程计。
因此,对于每个时间步t,都有一个运动模型\(P(x_t|x_{t-1},u_{t-1})\)。此外,在每个时刻t,我们都有来自LiDAR和cameras的语义扫描\(z_t\),为了定义我们的粒子滤波器,我们必须先定义观测模型\(P(z_{t}|x_{t})\)
运动模型
实际上,我们并不能获取真正的控制输入量,而是从frame-to-frame的估计中获取一个近似。
因为UPSLAM在3D空间中操作,因此我们首先将帧间运动投影到local的x-y地平面上,记为\(\operatorname{proj}(u) \in SE(2)\)。此外,我们只使用UPSLAM的基于ICP的初始解作为运动估计,忽略了来自闭环后的优化位姿(这是为了避免里程的运动不连续性)。
最后,我们假设分布具有恒定的协方差,在log-space中具有尺度噪声,因此,有:
\[ \begin{aligned} P\left(x_{t} \mid x_{t-1}, u_{t-1}\right)=(&\left[\operatorname{proj}\left(u_{t-1}\right)+\mathcal{N}\left(0, \Sigma_{p}\right)\right] * p_{t-1},\left.\mathcal{N}\left(1, \Sigma_{s}\right) * s_{t-1}\right) \end{aligned} \]
另外,我们使用到起点位置的距离的inverse来对协方差\(\Sigma_s\)进行缩放,以使得可以自然的收敛。一旦尺度方差低于阈值,我们则可固定尺度s。
观测模型
我们的观测\(z\)是语义的点云,我们可以表示为在机器人坐标系中具有相关性的标签:\(z=\{ (p_1,l_1),(p_2,l_2),\dots,(p_n,l_n) \}\)。因此,我们可以将这些点投影到地平面上。
进一步的,对于任意给定的粒子状态,我们可以对机器人坐标系中的点在俯视的空中地图\(L\)中查询,比较地图上的类别与预期类别,在给定粒子状态(位姿为\(d\))的条件下,一个简单的计算cost方法如下:
\[ C^{\prime}=\sum_{i \in[1, n]} \mathbf{1}\left(L\left(d * p_{i}\right) \neq l_{i}\right) \]
为了通过扩大局部最小来提高收敛性,我们选择一个更柔软的成本函数。因此,我们不使用以二进制方式评估cost,而是以机器人坐标系中的点对应的类别为目标类别,在空中地图中查询相同类别的最近点,以两点距离作为cost:
\[ C=\sum_{i \in[1, n]} \min _{\left\{p \mid L(p)=l_{i}\right\}}\left(\left\|p-p_{i}\right\|\right) \]
最后,我们通过对\(C\)求逆和正则化来计算一个ad-hoc probability,另外,对于每一个类别的点,可以设置一个权重因子\(\alpha_l\):
\[ P\left(z_{t} \mid x_{t}\right) \approx \frac{n}{\sum_{i \in[1, n]} \min _{\left\{p \mid L(p)=l_{i}\right\}}\left(\alpha_{l_{i}}\left\|p-p_{i}\right\|\right)}+\gamma \]
其中,\(\gamma\)是正则化常数项,用于slow convergence??? 所有粒子的概率最后都要进行归一化,以使得所有粒子对应的观测模型概率之和为1。
可以注意到,这是一个ad-hoc观测,在实践中可以通过实验对常数进行调整,然而,这对于基于蒙特卡罗的定位方法并不少见,例如 [29]。
性能优化
如果单纯的实现\(C^{\prime}\)的cost计算,将会导致较大计算成本,因为它总结了所有的非凸最小值的情况。我们通过预先计算空中语义地图关于类别的截断场(Truncated Distance Field, TDF)来优化这个问题,这个计算非常直观,大概需要1分钟,但是只需要进行一次。
这个TDF地图对每一个点到其同类别的最近点的距离阈值进行编码,将最小化\(C^{\prime}\)变成了一个简单的查表。另外,相比于简单的对所有点的结果进行求和,使用了如下方法优化:首先将语义激光扫描分散到极坐标系中,统计在每个极坐标系分割中每个类别的点数。然后局部的类别TDF场使用同种方式渲染显示。然后通过对两个图像的元素进行乘法,得到关于每个类别的内积,来近似\(C^{\prime}\)的计算,提高计算效率。
我们发现,对于100x25像素的极坐标地图,每个粒子大概需要500μs来计算,几乎是用于查表的时间,如图3所示。
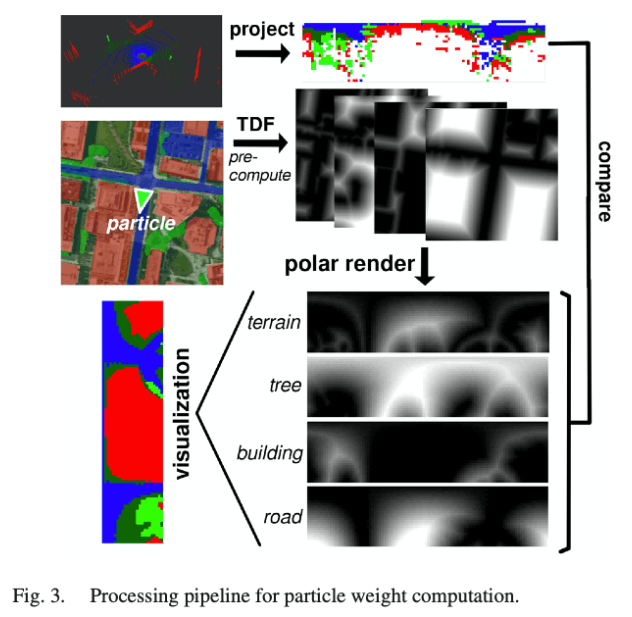
另外,地图的旋转在极坐标中表示为索引的偏移,计算非常快,可用于初始化阶段。我们随机采样了地图上的道路点,因为我们有强壮的先验信息:因为是从道路上开始的。对于每一个点,我们初始化\(k_s\)个在\(s_{min}\)和\(s_{max}\)(1~10 px/m)尺度内均匀分布的粒子。对于每一个粒子,我们采样\(k_{\theta}\)个可能的观测,使得我们可以高效的对索引进行偏移(可参考scan-context),然后选取最佳的观测作为初始粒子。
为了进一步加速算法,我们使用CPU并行计算每个粒子的cost,我们还基于高斯混合模型(GMM)的协方差的区域的总和适应粒子分布的基础上的粒子数
语义分割
卫星分割
我们使用在 ImageNet 上预训练的 ResNet-34 [34] 骨干训练两个稍微修改过的完全卷积网络 (FCN) [33] 版本以分割卫星图像,图像直接从Google-Earth中获取。
我们使用了4个类别:
- road(道路)
- terrain(地面)
- vegetation(植被)
- building(建筑)
为了分析卫星图像,256×256 PX RGB图像被传递为图像分割网络的输入,该网络由3个手工标注的卫星图像数据训练得到,如表1所示。
图像是随机缩放,旋转,裁剪的,并翻转以产生更多的训练样本,卫星图像的随机缩放也允许模型在从多个高度收集的图像上概率更好地泛化。
网络输出例子和训练数据如图5所示。

令人惊讶的是,尽管模型只在3张图片上训练,但是每张图片都包含了许多对象实例
激光扫描分割
我们使用图 2 中绿色方框中显示的两个不同的pipline,用于根据数据集生成语义点云。通过使用不同的分割方法进行测试,展示了我们的方法可以适用于不同的传感系统,提供点级别的标签点云。
PC 对于kitti数据集,使用了与卫星图像分割同样的FCN结构,对于激光扫描,使用带有X,Y,Z,Depth通道的64x2048的2D-Poloar-Grid-Map来表示(没有利用强度信息)。
我们在SemanticKITTI数据集上训练,然后使用序列{10}和{00,02,09}作为验证集和测试集。另外,我们添加地面车辆转化为road类别。
RGB
对于我们自己的Morgantown和Ucity数据集,我们使用不同于Kitti的激光雷达(Ouster OS-1),因此不能使用Semantickitti进行训练。因此,我们使用HRNets[13]来对RGB图像进行分割,然后校准到激光扫描中。利用外参信息,可以将激光点云投影到相机图像帧,然后根据RGB的分割对点云进行分配。
建图
我们使用UPSLAM,但此处给出了在本工作中的一些更改的概况。对于这项工作,我们扩展了UPSLAM,整合从图像中提取的语义标签,以形成语义全景。需要注意的是,UPSLAM并没有使用语义信息来进行scan-matching,只是简单的使用刚体变换信息来整合语义信息。因此,由于我们不需要每一帧扫描的语义数据,我们可以以低于LIDAR的速率来运行推断,而无需删除ICP数据,以提高地图质量。深度、法向量、语义全景如图4所示。

除了使用UPSLAM估计的粒子过滤器运动模型之外,我们还计算每个更新的后粒子滤波器估计的协方差和均值。一旦协方差低于阈值\(\Sigma_t\),我们使用粒子滤波器估计的位置作为位子图中对应状态节点的先验,最终得到如图2所示的pose graph。
通过这样的方式,我们使得图优化结果与地理保持对齐,我们的实验表明,添加这些语义约束边可去除漂移,并有效地构建语义闭环约束。这使得建图器在没有闭环的情况下可以应对更大规模的轨迹,并保持全局一致性。
实验

参考文献
[1] W.Maetal.,“Findyourwaybyobservingthesunandothersemanticcues,”in Proc. IEEE Int. Conf. Robot. Automat., May 2017, pp. 6292–6299. [2] T. Dang et al., “Autonomous search for underground mine rescue using aerial robots,” in Proc. IEEE Aerosp. Conf., 2020, pp. 1–8. [3] A. Gawel et al., “3D registration of aerial and ground robots for disaster response: An evaluation of features, descriptors, and transformation esti- mation,” in Proc. IEEE Int. Symp. Saf., Secur. Rescue Robot., Oct. 2017, pp. 27–34. [4] J. Peterson et al., “Online aerial terrain mapping for ground robot naviga- tion,” Sensors, vol. 18, no. 2, Feb. 2018, Art no. 630. [5] N. Michael et al., “Collaborative mapping of an earthquake-damaged building via ground and aerial robots,” J. Field Robot., vol. 29, no. 5, pp. 832–841, 2012. [6] X. Liang, H. Wang, Y. Liu, W. Chen, and T. Liu, “Formation control of non- holonomic mobile robots without position and velocity measurements,”IEEE Trans. Robot., vol. 34, no. 2, pp. 434–446, Apr. 2018. [7] A. Franchi, G. Oriolo, and P. Stegagno, “Mutual localization in multi- robot systems using anonymous relative measurements,” Int. J. Robot. Res., vol. 32, no. 11, pp. 1302–1322, 2013. [8] A. Howard, “Multi-robot simultaneous localization and mapping using particle filters,” Int. J. Robot. Res., vol. 25, no. 12, pp. 1243–1256, 2006. [9] S. Wang et al., “A novel approach for lidar-based robot localization in a scale-drifted map constructed using monocular slam,” Sensors, vol. 19, no. 10, 2019, Art. no. 2230. [10] F. Dellaert, D. Fox, W. Burgard, and S. Thrun, “Monte Carlo localization for mobile robots,” in Proc. IEEE Int. Conf. Robot. Automat., vol. 2, 1999, pp. 1322–1328 vol.2. [11] A. L. Majdik, Y. Albers-Schoenberg, and D. Scaramuzza, “MAV urban localization from google street view data,” in Proc. IEEE/RSJ Int. Conf. Intell. Robots Syst., Nov. 2013, pp. 3979–3986. [12] X. Gao, S. Shen, Z. Hu, and Z. Wang, “Ground and aerial meta-data integration for localization and reconstruction: A review,” Adv. Visual Corresp.: Models, Algorithms Appl., Pattern Recognit. Lett. vol. 127, pp. 202–214, 2019. [13] J. Wang et al., “Deep high-resolution representation learning for visual recognition,” IEEE Trans. Pattern Anal. Mach. Intell., early access: Apr. 01, 2020, doi: 10.1109/TPAMI.2020.2983686. [14] M. Wu, C. Zhang, J. Liu, L. Zhou, and X. Li, “Towards accurate high resolution satellite image semantic segmentation,” IEEE Access, vol. 7, pp. 55 609–55 619, 2019. [15] F. Castaldo, A. Zamir, R. Angst, F. Palmieri, and S. Savarese, “Semantic cross-view matching,” in Proc. IEEE Int. Conf. Comput. Vis. Workshops, Dec. 2015, pp. 9–17. [16] A. Gawel, C. D. Don, R. Siegwart, J. Nieto, and C. Cadena, “X-view: Graph-based semantic multi-view localization,” IEEE Robot. Automat. Lett., vol. 3, no. 3, pp. 1687–1694, Jul. 2018. [17] J. Behley et al., “SemanticKITTI: A dataset for semantic scene under- standing of LiDAR sequences,” in Proc. IEEE/CVF Int. Conf. Comput. Vis., 2019, pp. 9297–9307. [18] D.M. Chen et al., “City-scale landmark identification on mobile devices,”in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., Jun. 2011, pp. 737–744. [19] Y. Li, N. Snavely, and D. P. Huttenlocher, “Location recognition using prioritized feature matching,” Computer Vision – ECCV, K. Daniilidis, P. Maragos, and N. Paragios, eds. Springer Berlin Heidelberg, 2010, pp. 791–804. [20] D. Kim and M. R. Walter, “Satellite image-based localization via learned embeddings,” in Proc. IEEE Int. Conf. Robot. Automat., May 2017, pp. 2073–2080. [21] Y. Tian, X. Deng, Y. Zhu, and S. Newsam, “Cross-time and orientation- invariant overhead image geolocalization using deep local features,” in Proc. IEEE Winter Conf. Appl. Comput. Vis., 2020, pp. 2512–2520. [22] K. Y. K. Leung, C. M. Clark, and J. P. Huissoon, “Localization in urban environments by matching ground level video images with an aerial image,” in Proc. IEEE Int. Conf. Robot. Automat., May 2008, pp. 551–556. [23] T. Senlet and A. Elgammal, “A framework for global vehicle localization using stereo images and satellite and road maps,” in Proc. IEEE Int. Conf. Comput. Vis. Workshops, Nov. 2011, pp. 2034–2041. [24] R. W. Wolcott and R. M. Eustice, “Visual localization within lidar maps for automated urban driving,” in Proc. IEEE/RSJ Int. Conf. Intell. Robots Syst., Sep. 2014, pp. 176–183. [25] I. A. Barsan, S. Wang, A. Pokrovsky, and R. Urtasun, “Learning to localize using a lidar intensity Map,” in Proc. 2nd Conf. Robot Learn., Proc. Mach. Learn. Res., A. A. Billard Dragan, J. Peters, and J. Morimoto, Eds. PMLR, 29-31, vol. 87, Oct. 2018, pp. 605–616. [26] B. C. Matei et al., “Image to LiDar matching for geotagging in urban environments,” in Proc. IEEE Workshop Appl. Comput. Vis., Jan. 2013, pp. 413–420. [27] T. Senlet, T. El-Gaaly, and A. Elgammal, “Hierarchical semantic hashing: Visual localization from buildings on maps,” in Proc. 22nd Int. Conf. Pattern Recognit., Aug. 2014, pp. 2990–2995. [28] Y. Tian, C. Chen, and M. Shah, “Cross-view image matching for geo- localization in urban environments,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., Jul. 2017, pp. 3608–3616. [29] F. Yan, O. Vysotska, and C. Stachniss, “Global localization on open- streetmap using 4-bit semantic descriptors,” in Proc. Eur. Conf. Mobile Robots, 2019, pp. 1–7. [30] E. Stenborg, C. Toft, and L. Hammarstrand, “Long-term visual localization using semantically segmented images,” in Proc. IEEE Int. Conf. Robot. Automat., 2018, pp. 6484–6490. [31] Y. Liu, Y. Petillot, D. Lane, and S. Wang, “Global localization with object- level semantics and topology,” in Proc. Int. Conf. Robot. Automat., 2019, pp. 4909–4915. [32] A. Cowley, I. D. Miller, and C. J. Taylor, “UPSLAM: Union of panoramas SLAM,” in Proc. Int. Conf. Robot. Automat., 2021. [33] J. Long, E. Shelhamer, and T. Darrell, “Fully convolutional networks for semantic segmentation,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2015, pp. 3431–3440. [34] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2016, pp. 770–778. [35] M. Cordts et al., “The cityscapes dataset for semantic urban scene un- derstanding,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2016, pp. 3213–3223. [36] A. Geiger, P. Lenz, and R. Urtasun, “Are we ready for autonomous driving? The KITTI vision benchmark suite,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2012, pp. 3354–3361. [37] S. S. Shivakumar, T. Nguyen, I. D. Miller, S. W. Chen, V. Kumar, and C. J. Taylor, “Dfusenet: Deep fusion of RGB and sparse depth information for image guided dense depth completion,” in Proc. IEEE Intell. Transp. Syst. Conf., 2019, pp. 13–20.