LeGO-LOAM: Lightweight and Ground-Optimized Lidar Odometry and Mapping on Variable Terrain

摘要
提出了一种轻量级的,地面优化的激光雷达里程计和建图方法——LeGO-LOAM,一种实时的六自由度的地面车辆位姿估计工具。
LeGO-LOAM是轻量级的,可以在低算力的嵌入式设备中达到实时的位姿估计,同时,也是地面优化的,在分割和优化步骤中,利用了地面信息的存在来加以优化。
首先应用点云分割来滤除噪声,然后特征提取,获得平面特征和边缘特征。一个两步的Levenberg-Marquardt优化方法,然后根据平面和边缘的特征,来求解连续扫描帧之间的六个自由度的变换。
我们使用LeGO-LOAM与当前先进的LOAM进行对比,使用从variable-terrain收集的地面车辆数据集,然后展示了LeGO-LOAM达到了相似或更好的准确度,并且减少了计算量。
我们也整合了LeGO-LOAM到SLAM框架中,来消除漂移导致的位姿估计误差。
介绍
- 第一步中,从地面获取的平面特征用来获得观测\([t_z,\theta_{roll},\theta_{pitch}]\)
- 第二步中,剩下的\([t_x,t_y,\theta_{yaw}]\)通过匹配边缘特征(从分割的点云中获取的)来观测得到
我们也整合了回环检测功能来修正运动估计的漂移。
测试系统硬件
VLP-16(测量距离100米,准确度+-3m,垂直视场角+-15度,水平视场角360度),16线雷达提供了垂直的角度分辨率为2度,水平分辨率0.1度到0.4度,基于旋转的速率
HDL-64E(KITTI数据集中),垂直视场角26.9度,水平360度,但是有48线
I7-4710MQ,2.5Ghz
TX2——ARM Cortex-A57 CPU
系统概述
全系统概况
提出的框架如图1所示
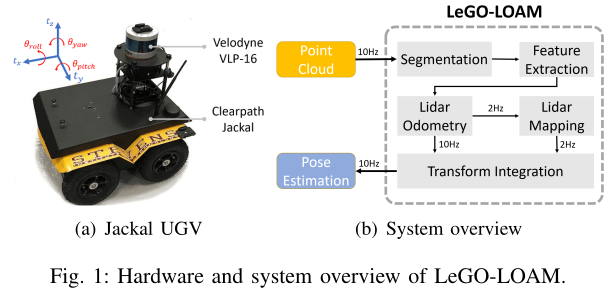
全系统分为5个部分
- (1)分割 取一帧扫描点云,然后投影到range Image用来进行分割(分段),分割之后的点云被送到特征提取模块
- (2)特征提取 对range Image进行特征提取,提取平面和线特征?
- (3)lidar Odometry 使用提取得到的特征,寻找连续两帧之间的变换
- (4)lidar Mapping 这些特征进一步的交给lidar mapping来处理,对他们进行全局的配准
- (5)整合 最后,融合
lidar Odometry和lidar Mapping模块的位姿估计,输出最终的位姿估计
提出的框架是为了提高地面车辆的位姿估计的效率和准确度
分割模块
令\(P_t={p_1,p_2,\cdots,p_n}\)为在t时刻获得的点云,其中\(p_i\)是点云\(P_t\)中的一个点。
\(P_t\)首先被投影到range Image上,分辨率是1800×16(360/0.2×16),因为VLP-16的水平和垂直角分辨率是0.2度和2度。点云中每一个有效点\(p_i\)在深度图中使用一个独特的像素点来表示。深度值\(r_i\)与点\(p_i\)所代表的点\(p_i\)到传感器的欧式距离有关。
由于斜坡地形在许多环境中都很常见,所以我们不假定地面是平的。
对距离图像进行按列估计,可看作是对地平面的估计,因此在分割之前,进行地面点提取。
经过这一步处理,可能代表地面的点被标记为ground,然后不参与下一步分割。
然后,将一种基于图像的分割方法[23]应用到深度图中,将点分组成多个簇,同一簇的点被分配得到一个独特的label。注意,地面点是一个特殊的簇。
对点云进行分割,有利于提高后面处理效率和特征提取的准确度。假设机器人在噪声较大的环境下运行,小的物体如树叶,可能会形成一些琐碎且不可靠的特征,因为在连续两次扫描中不太可能看到。
为了对点云进行快速可靠的特征提取,我们忽略小于30个点的簇,分割前后的点云如图2所示
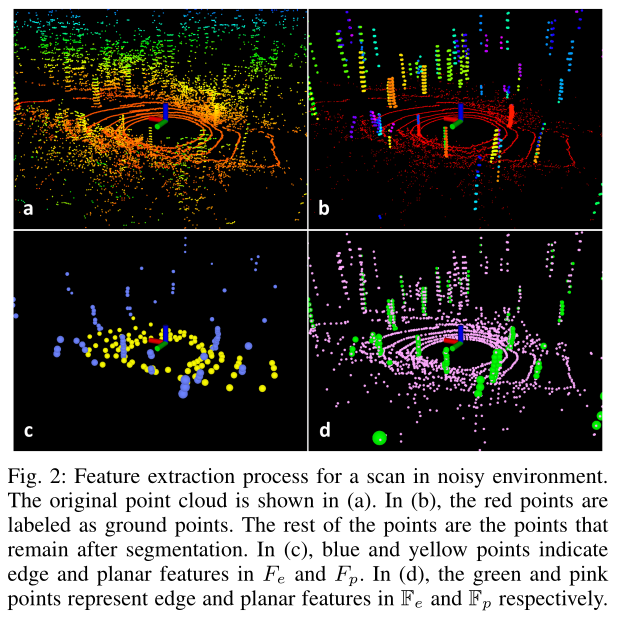
原始的点云包含许多点,这些点是从周围的植被中获得的,这些植被可能产生不可靠的特征。
经过处理之后,仅有图2(b)所示的点云可能包含着大的物体,如卡车和地面点,这些用于进一步的处理,同时,深度图也仅仅保留这部分点的信息。
我们同时有了每个点的3个属性
- 标签(地面点标签、分割的标签)
- 深度图中的行和列索引
- 代表的距离值
特征提取
特征提取与文献[20]相似,不同的是,我们从地面点和点云分割之后点进行特征提取,而不是对原始点云数据进行特征提取。
令\(\mathcal{S}\)作为深度图中与点\(p_i\)同一行的连续点集合。
有一半的点是点\(p_i\)的另一面(另一个方向)。在本文,设置\(|S|\)为10
我们可以计算出S中点\(p_i\)的粗糙度

- 计算每个点\(p_i\)的粗糙度,令S作为range image中同一行的连续点\(p_i\)的点集
- 为了从所有方向均匀地提取特征,将range image水平划分为几个相等的sub-image
- 按每个点的粗糙度值 对sub-image的每一行中的点进行排序
- 使用阈值\(c_{th}\)来区分不同特征的类别,大于阈值的,被认为是边特征,小于阈值的则被认为是平面特征。
- 从sub-image的每一行中选取不属于地面,且有前\(n_{\mathbb{F}_e}\)个最大c值的边特征
- 从sub-image的每一行中选取前\(n_{\mathbb{F}_p}\)个最小c的平面特征点(可以标记为地面或分段点)
- \(\mathbb{F}_e\)和\(\mathbb{F}_p\)为所有sub-image的边缘和平面特征集合,如图2(d)
- 从子图中的每一行提取具有最大c的\(n_{Fe}\)个边缘特征,他们肯定不属于地面
- 从子图中的每一行提取具有最小c的\(n_{Fp}\)个平面特征,他们肯定是地面点
- 前两步(8,9)产生了绝对的边缘集合\(F_e\)和平面集合\(F_p\),特征如图2(c),其中,\(F_e \subset \mathbb{F}_e,F_p \subset \mathbb{F}_p\)
将360°范围图像分为6个子图像。每个子图像的分辨率为300x16。令\(n_{Fe}=2,n_{Fp}=4,n_{\mathbb{F}_e}=40,n_{\mathbb{F}_p}=80\)
激光里程计
激光雷达测程模块估计两个连续扫描之间传感器的运动。通过点-边和点-面扫描匹配,实现了连续两帧扫描之间的变换关系.
换句话说,需要从前一帧的\(\mathbb{F}_e^{t-1},\mathbb{F}_{p}^{t-1}\)找到当前帧的绝对特征\(F_e^t,F_p^t\)点的关联
改进点
- 标签匹配: 因为\(F_e^t,F_p^t\)中的每个特征都有标签,我们只从\(\mathbb{F}_e^{t-1},\mathbb{F}_{p}^{t-1}\)找具有相同标签的关联。 对于\(F_p^t\)中的平面特征,只有\(\mathbb{F}_{p}^{t-1}\)中被标记为地面的点才用来寻找关联。 对于\(F_e^t\)中的边缘特征,只从\(\mathbb{F}_e^{t-1}\)寻找对应的边缘关联。 这种方式提高匹配准确性,缩小了潜在对应特征的数量。
- 两步LM优化
- 将\(F_p^t\)中的平面点和\(\mathbb{F}_{p}^{t-1}\)中的特征相匹配,估计得到\([t_z,\theta_{roll},\theta_{pitch}]\)
- 将\(F_e^t\)中的边缘点与\(\mathbb{F}_e^{t-1}\)中的特征点进行匹配,加上前一步估算的\([t_z,\theta_{roll},\theta_{pitch}]\)作为附加条件,得到剩下的\([t_x,t_y,\theta_{yaw}]\)
- 虽然\([t_x,t_y,\theta_{yaw}]\)也可以放在第一步进行,但是这样准确度不高,得到的结果难以在第二步中使用
- 两个连续扫描之间的6自由度通过对\([t_z,\theta_{roll},\theta_{pitch}]\)和\([t_x,t_y,\theta_{yaw}]\)融合得到
- 两步LM优化,可以达到相同的精度,计算时间减少35%
激光建图
建图模块以较低的频率运行,匹配\(\{\mathbb{F}_e^{t},\mathbb{F}_{p}^{t}\}\)中的特征到之前获得的附近的点云地图\(\bar{Q}^{t-1}\)上,来优化位姿估计。然后使用LM迭代,再次进行全局优化
详细的匹配和优化过程,阅读文献[20]
LEGO-LOAM一个主要的不同是,如何存储最终点云图:采用的是单独地储存特征集合\(\{\mathbb{F}_e^{t},\mathbb{F}_{p}^{t}\}\),而不是储存单个完整的点云地图。
例如,\(M^{t-1}=\{\{\mathbb{F}_e^{1},\mathbb{F}_{p}^{1}\}\cdots,\{\mathbb{F}_e^{t-1},\mathbb{F}_{p}^{t-1}\} \}\)表示以前的所有特征集合的集合,\(M^{t-1}\)中的每个特征集合都与该时刻的激光雷达位姿相关联,然后从\(M^{t-1}\)获取点云地图\(\bar{Q}^{t-1}\)有两种方法
一,和Zhang Ji论文类似,选择在传感器视野里面的特征点集获得\(\bar{Q}^{t-1}\),为了简化,我们选择当前传感器位置100米范围内的特征集合,被选择的特征集合经过变换然后融合到一个点云地图\(\bar{Q}^{t-1}\)中
二,在LeGO-LOAM中集成了图优化的方法 1) 图的节点: 每个特征集合对应的传感器位姿 特征集合\(\{\mathbb{F}_e^{t},\mathbb{F}_{p}^{t}\}\)被看作为这个节点上的传感器测量数据 2) 激光雷达建图模型的位姿估计漂移一般比较低,可以假设在短时间内没有位姿漂移(drift)。通过选择一组最近几帧的特征集合来构成点云地图\(\bar{Q}^{t-1}\),如\(\bar{Q}^{t-1}=\{\{\mathbb{F}_e^{t-k},\mathbb{F}_{p}^{t-k}\}\cdots,\{\mathbb{F}_e^{t-1},\mathbb{F}_{p}^{t-1}\} \}\),其中,k表示选取集合的数量 3) 新的节点(当前帧位姿)和\(\bar{Q}^{t-1}\)中被选择的节点之间加上空间约束,(通过前端LM变换得到的坐标变换) 4) 使用回环检测(loop closure)进一步消除雷达建图的漂移,如果用ICP发现当前特征集和先前特征集之间有匹配,则添加新约束,然后通过将Pose Graph发送到如[24](iSAM2)的优化系统来更新位姿估计。