- 1. SLAM基础知识点
- 1.1. SIFT和SUFT的区别
- 1.2. 相似变换、仿射变换、射影变换的区别
- 1.3. Homography、Essential和Fundamental Matrix的区别
- 1.4. 视差与深度的关系
- 1.5. 描述PnP算法
- 1.6. 闭环检测常用方法
- 1.7. 给一个二值图,求最大连通域
- 1.8. 梯度下降法、牛顿法、高斯-牛顿法的区别
- 1.9. 推导一下卡尔曼滤波、描述下粒子滤波
- 1.10. 如何求解Ax=b的问题
- 1.11. 什么是极线约束
- 1.12. 单目视觉SLAM中尺寸漂移是怎么产生的
- 1.13. 解释SLAM中的绑架问题
- 1.14. 描述特征点法和直接法的优缺点
- 1.15. EKF和BA的区别
- 1.16. 边缘检测算子有哪些?
- 1.17. 简单实现cv::Mat()
- 1.18. 10个相机同时看到100个路标点,问BA优化的雅克比矩阵多少维
- 1.19. 介绍经典的视觉SLAM框架
- 1.20. 室内SLAM与自动驾驶SLAM有什么区别?
- 1.21. 什么是紧耦合、松耦合?优缺点。
- 1.22. 地图点的构建方法有哪些
- 1.23. 如果对于一个3D点,我们在连续帧之间形成了2D特征点之间的匹配,但是这个匹配中可能存在错误的匹配。请问你如何去构建3D点?
- 1.24. RANSAC在选择最佳模型的时候用的判断准则是什么?
SLAM基础知识点
SIFT和SUFT的区别
构建图像金字塔: SIFT特征利用不同尺寸的图像与高斯差分滤波器卷积;SURF特征利用原图片与不同尺寸的方框滤波器卷积
特征描述子:SIFT特征有4×4×8=128维描述子,SURF特征有4×4×4=64维描述子
特征点检测方法:SIFT特征先进行非极大抑制,再去除低对比度的点,再通过Hessian矩阵去除边缘响应过大的点;SURF特征先利用Hessian矩阵确定候选点,然后进行非极大抑制
特征点主方向: SIFT特征在正方形区域内统计梯度幅值的直方图,直方图最大值对应主方向,可以有多个主方向;SURF特征在圆形区域内计算各个扇形范围内x、y方向的haar小波响应,模最大的扇形方向作为主方向
相似变换、仿射变换、射影变换的区别
等距变换:相当于是平移变换(t)和旋转变换(R)的复合,等距变换前后长度,面积,线线之间的角度都不变。自由度为6(3+3)
相似变换:等距变换和均匀缩放(S)的一个复合,类似相似三角形,体积比不变。自由度为7(6+1)
仿射变换:一个平移变换(t)和一个非均匀变换(A)的复合,A是可逆矩阵,并不要求是正交矩阵,仿射变换的不变量是:平行线,平行线的长度的比例,面积的比例。自由度为12(9+3)
射影变换:当图像中的点的齐次坐标的一般非奇异线性变换,射影变换就是把理想点(平行直线在无穷远处相交)变换到图像上,射影变换的不变量是:重合关系、长度的交比。自由度为15(16-1)
参考:多视图几何总结——等距变换、相似变换、仿射变换和射影变换
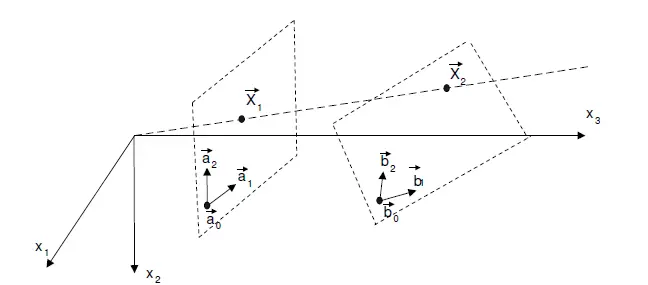
Homography、Essential和Fundamental Matrix的区别
Homography Matrix可以将一个二维射影空间的点变换该另一个二维射影空间的点,如下图所示,在不加任何限制的情况下,仅仅考虑二维射影空间中的变换,一个单应矩阵H HH可由9个参数确定,减去scale的一个自由度,自由度为8。
Fundamental Matrix对两幅图像中任何一对对应点x和x′基础矩阵F都满足条件:
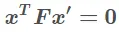
,秩只有2,因此F的自由度为7。它自由度比本质矩阵多的原因是多了两个内参矩阵。
Essential matrix:本质矩是归一化图像坐标下的基本矩阵的特殊形式,其参数由运动的位姿决定,与相机内参无关,其自由度为6,考虑scale的话自由度为5。
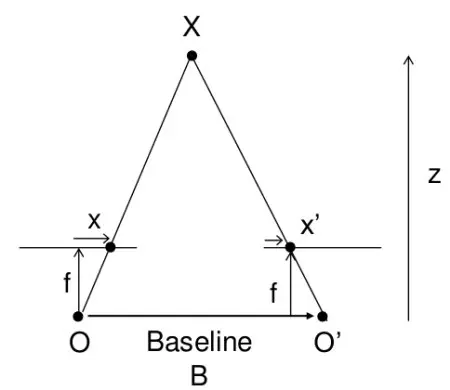
视差与深度的关系
在相机完成校正后,则有 \(\frac{d}{b}=\frac{f}{z}\) ,其中d表示视差,b表示基线,f是焦距,z是深度。这个公式其实很好记,在深度和焦距确定的情况下,基线越大,视差也会越大。
描述PnP算法
已知空间点世界坐标系坐标和其像素投影,公式如下:
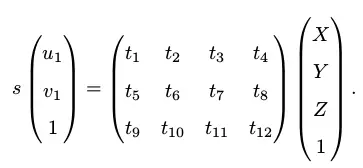
目前一共有两种解法,直接线性变换方法(一对点能够构造两个线性约束,因此12个自由度一共需要6对匹配点),另外一种就是非线性优化的方法,假设空间坐标点准确,根据最小重投影误差优化相机位姿。
目前有两个主要场景场景,
- 其一是求解相机相对于某2维图像/3维物体的位姿;
- 其二就是SLAM算法中估计相机位姿时通常需要PnP给出相机初始位姿。
在场景1中,我们通常输入的是物体在世界坐标系下的3D点以及这些3D点在图像上投影的2D点,因此求得的是相机坐标系相对于世界坐标系(Twc)的位姿
在场景2中,通常输入的是上一帧中的3D点(在上一帧的相机坐标系下表示的点)和这些3D点在当前帧中的投影得到的2D点,所以它求得的是当前帧相对于上一帧的位姿变换
闭环检测常用方法
ORB-SLAM中采用的是词袋模型进行闭环检测筛选出候选帧,再通过求解Sim3来解决尺度漂移问题,最后再判断最合适的关键帧
LSD-SLAM中的闭环检测主要是根据视差、关键帧连接关系,找出候选帧,然后对每个候选帧和测试的关键帧之间进行双向Sim3跟踪,如果求解出的两个李代数满足马氏距离在一定范围内,则认为是闭环成功
给一个二值图,求最大连通域
二值图的连通域应该是用基于图论的深度优先或者广度优先的方法,后来还接触过基于图的分割方法,采用的是并查集的数据结构,之后再作细致对比研究
梯度下降法、牛顿法、高斯-牛顿法的区别
考虑一个简单的最小二乘问题:
\[ argmin \frac{1}{2} ||f(x)||_2^2 \]
如果函数f(x)很简单,那么或许这个问题可以使用解析解,令目标函数的导数为0,求解对应的x值即可,即
\[ \frac{d(\frac{1}{2}||f(x)||_2^2)}{dx}=0 \]
但是在BA优化、PnP、直接法里面,这些维度通常很大,是非线性优化问题,上面几种方法都是针对对非线性优化问题提出的方法。
对目标函数在x附近进行泰勒展开,得到:
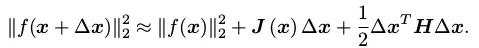
我们可以选择保留泰勒展开的一阶项或者二阶项,分别对应一阶梯度法和二阶梯度法(牛顿法)
- 梯度下降法是一个一阶最优化算法,通常也称为最速下降法。 要使用梯度下降法找到一个函数的局部极小值,必须向函数上当前点对应梯度(或者是近似梯度)的反方向的规定步长距离点进行迭代搜索。因此指保留一阶梯度信息。缺点是过于贪心,容易走出锯齿路线。
保留泰勒展开的一阶项,然后求导等于0,即可求的梯度方向:
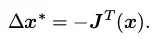
- 牛顿法是一个二阶最优化算法,基本思想是利用迭代点处的一阶导数(梯度)和二阶导数(Hessen矩阵)对目标函数进行二次函数近似。因此保留二阶梯度信息。缺点是需要计算H矩阵,计算量太大。
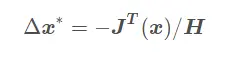
其常见的表达如下(二者等价,在解附近是二阶收敛的):
\[ \Delta x = - \frac{f(x0)}{f(x0)'} \]
而把非线性问题,先进行一阶展开,然后再作平方处理就可以得到高斯-牛顿法和列文博格方法:
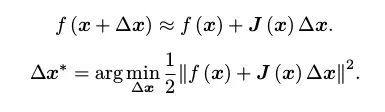
- 高斯-牛顿法对上式展开并对Δx进行求导即可得高斯牛顿方程,其实其就是使用\(JJ^T\)来近似牛顿法的H矩阵,但是\(JJ^T\)有可能为奇异矩阵或变态,Δx也会造成结果不稳定,因此稳定性差。
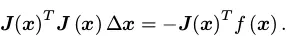
- 列文博格法就是在高斯-牛顿法的基础上对Δx添加一个信赖区域,保证其只在展开点附近有效,即其优化问题变为带有不等式约束的优化问题,利用Lagrange乘子求解
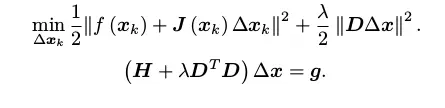
推导一下卡尔曼滤波、描述下粒子滤波
卡尔曼滤波:
卡尔曼滤波就是通过运动方程获得均值和方差的预测值,然后结合观测方程和预测的方差求得卡尔曼增益,然后在用卡尔曼增益更行均值和方差的预测值而获得估计值。
卡尔曼滤波推导的思路是(其中一种)先假定有这么一个修正公式
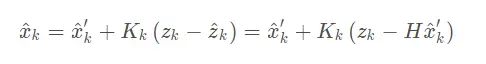
根据真实值和估计值之间的协方差矩阵,然后通过对对角线元素求和获得方差表达式,我们的修正公式是需要使得方差最小,因此把方差表达式对\(K_k\)求导就可以获得卡尔曼增益的表达式,然后从先验到预测值的方差公式可以通过求预测值和真实值的协方差矩阵获得。
粒子滤波
粒子滤波最常用的是SIR(重要性重采样(Sampling Importance Resampling)),其算法是用运动方程获得粒子的状态采样,然后用观测方程进行权值更新,通过新的粒子加权平均就获得新的估计状态,最后非常重要的一步就是重采样。
粒子滤波的推导中概念有很多,最重要的推导过程是重要性采样过程,其思路就是我原本的采样分布是不知道的,我如何从一个已知的分布中采样,通过加权的方式使得从已知的分布中采样的粒子分布和原本未知的分布中采样的粒子分布结果一致,从而引入SIS粒子滤波,再进一步加入重采样后就引入了SIR粒子滤波。
如何求解Ax=b的问题
...
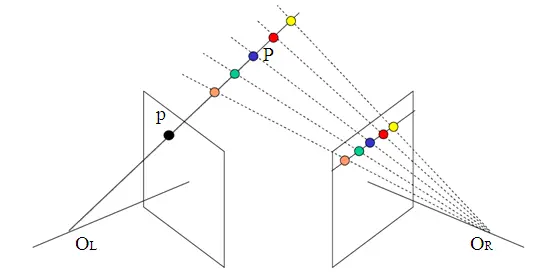
什么是极线约束
所谓极线约束就是说同一个点在两幅图像上的映射,已知左图映射点p1,那么右图映射点p2一定在相对于p1的极线上,这样可以减少待匹配的点数量。如下图
单目视觉SLAM中尺寸漂移是怎么产生的
用单目估计出来的位移,与真实世界相差一个比例,叫做尺度。这个比例在单目初始化时通过三角化确定,但单纯靠视觉无法确定这个比例到底有多大。由于SLAM过程中噪声的影响,这个比例还不是固定不变的。修正方式是通过回环检测计算Sim3进行修正。
解释SLAM中的绑架问题
绑架问题就是重定位,是指机器人在缺少之前位置信息的情况下,如何去确定当前位姿。例如当机器人被安置在一个已经构建好地图的环境中,但是并不知道它在地图中的相对位置,或者在移动过程中,由于传感器的暂时性功能故障或相机的快速移动,都导致机器人先前的位置信息的丢失,在这种情况下如何重新确定自己的位置。
初始化绑架可以阐述为一种通常状况初始化问题,可使用蒙特卡洛估计器,即粒子滤波方法,重新分散粒子到三维位形空间里面,被里程信息和随机扰动不断更新,初始化粒子聚集到/收敛到可解释观察结果的区域。追踪丢失状态绑架,即在绑架发生之前,系统已经保存当前状态,则可以使用除视觉传感器之外的其他的传感器作为候补测量设备。
描述特征点法和直接法的优缺点
特征点法:
优点:
- 没有直接法的强假设,更加精确;
- 相较与直接法,可以在更快的运动下工作,鲁棒性好
缺点:
- 特征提取和特征匹配过程耗时长;
- 特征点少的场景中无法使用;
- 只能构建稀疏地图
直接法:
优点:
- 省去了特征提取和特征匹配的时间,速度较快;
- 可以用在特征缺失的场合;
- 可以构建半稠密/稠密地图
缺点:
- 易受光照和模糊影响;
- 运动必须慢;
- 非凸性,易陷入局部极小解
EKF和BA的区别
- EKF假设了马尔科夫性,认为k时刻的状态只与k-1时刻有关。BA使用所有的历史数据,做全体的SLAM
- EKF做了线性化处理,在工作点处用一阶泰勒展开式近似整个函数,但在工作点较远处不一定成立。BA每迭代一次,状态估计发生改变,我们会重新对新的估计点做泰勒展开,可以把EKF看做只有一次迭代的BA
边缘检测算子有哪些?
边缘检测一般分为三步,分别是滤波、增强、检测。基本原理都是用高斯滤波器进行去噪,之后在用卷积内核寻找像素梯度。常用有三种算法:canny算子,sobel算子,laplacian算子
canny算子:一种完善的边缘检测算法,抗噪能力强,用高斯滤波平滑图像,用一阶偏导的有限差分计算梯度的幅值和方向,对梯度幅值进行非极大值抑制,采用双阈值检测和连接边缘。
sobel算子:一阶导数算子,引入局部平均运算,对噪声具有平滑作用,抗噪声能力强,计算量较大,但定位精度不高,得到的边缘比较粗,适用于精度要求不高的场合。
laplacian算子:二阶微分算子,具有旋转不变性,容易受噪声影响,不能检测边缘的方向,一般不直接用于检测边缘,而是判断明暗变化。
简单实现cv::Mat()
10个相机同时看到100个路标点,问BA优化的雅克比矩阵多少维
因为误差对相机姿态的偏导数的维度是2×6,对路标点的偏导数是2×3,又10个相机可以同时看到100个路标点,所以一共有10×100×2行,100×3+10×6个块。

介绍经典的视觉SLAM框架
g2o:
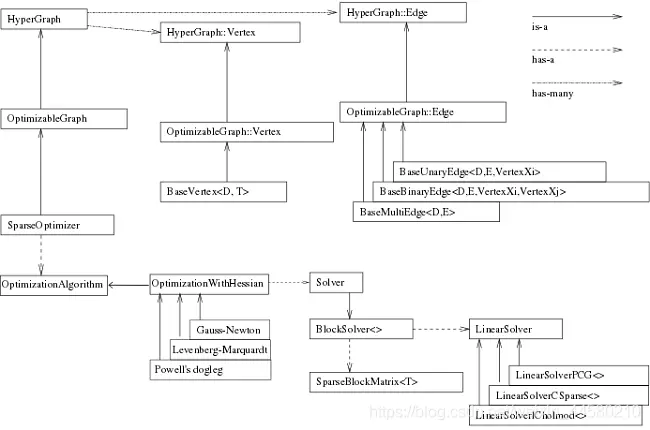
它表示了g2o中的类结构。
我们最终使用的optimizer是一个SparseOptimizer对象,因此我们要维护的就是它(对它进行各种操作)。 一个SparseOptimizer是一个可优化图(OptimizableGraph),也是一个超图(HyperGraph)。而图中有很多顶点(Vertex)和边(Edge)。顶点继承于BaseVertex,边继承于BaseUnaryEdge(一元边)、BaseBinaryEdge(二元边)或BaseMultiEdge。它们都是抽象的基类,实际有用的顶点和边都是它们的派生类。我们用SparseOptimizer.addVertex和SparseOptimizer.addEdge向一个图中添加顶点和边,最后调用SparseOptimizer.optimize完成优化。
在优化之前还需要制定求解器和迭代算法。一个SparseOptimizer拥有一个OptimizationAlgorithm,它继承自Gauss-Newton, Levernberg-Marquardt, Powell’s dogleg三者之一。同时,这个OptimizationAlgorithm拥有一个Solver,它含有两个部分:
- 一个是
SparseBlockMatrix,用于计算稀疏的雅可比和海塞矩阵; - 一个是线性方程求解器,可从PCG、CSparse、Choldmod三选一,用于求解迭代过程中最关键的一步:
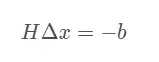
因此理清了g2o的结构,也就知道了其使用流程:
(1)选择一个线性方程求解器,PCG、CSparse、Choldmod三选一,来自g2o/solvers文件夹
(2)选择一个BlockSolver,用于求解雅克比和海塞矩阵,来自g2o/core文件夹
(3)选择一个迭代算法,GN、LM、DogLeg三选一,来自g2o/core文件夹
注意到上面的结构图中,节点Basevertex<D,T>,BaseBinaryEdge<D,E,VertexXi,VertexXj>和BlockSolver<>等都是模板类,我们可以根据自己的需要初始化不同类型的节点和边以及求解器,以ORB-SLAM2为例,分析下后端最典型的全局BA所用的边、节点和求解器:
(1)边是EdgeSE3ProjectXYZ,它其实就是继承自BaseBinaryEdge<2, Vector2d, VertexSBAPointXYZ, VertexSE3Expmap>,其模板类型里第一个参数是观测值维度,这里的观测值是其实就是我们的像素误差u,v u,vu,v,第二个参数就是我们观测值的类型,第三个第四个就是我们边两头节点的类型;
(2)相机节点VertexSE3Expmap,它其实就是继承自BaseVertex<6, SE3Quat>,其模板类第一个参数就是其维度,SE3是六维的这没毛病,第二个就是节点的类型,SE3Quat就是g2o自定义的SE3的类,类里面写了各种SE3的计算法则;
(3)空间点节点VertexSBAPointXYZ,它其实就是继承自BaseVertex<3, Vector3d>,其模板类第一个参数是说明咱空间点的维度是三维,第二个参数说明这个点的类型是Vector3d;
(4)求解器是BlockSolver_6_3,它其实就是BlockSolver< BlockSolverTraits<6, 3> >,6,3分别指代的就是边两边的维度了。
室内SLAM与自动驾驶SLAM有什么区别?
什么是紧耦合、松耦合?优缺点。
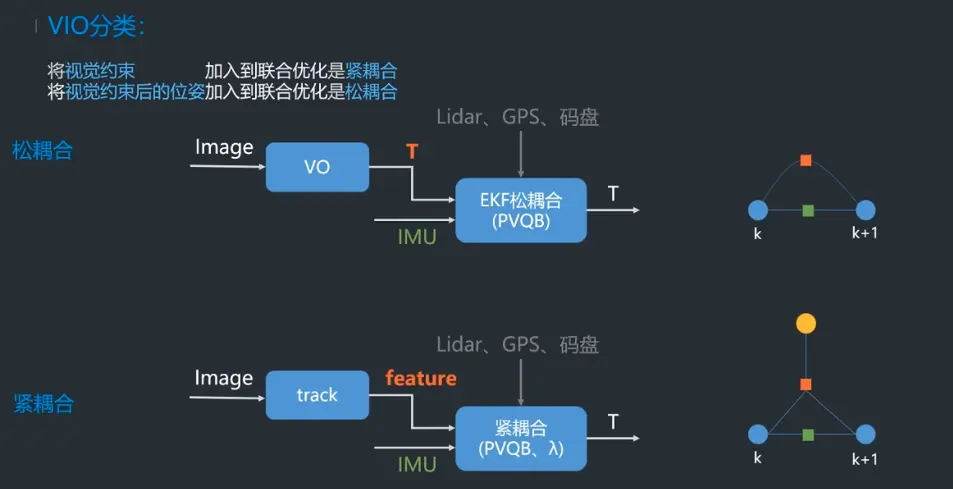
紧耦合是把图像的特征加到特征向量中去,这样做优点是可以免去中间状态的累计误差,提高精度,缺点是系统状态向量的维数会非常高,需要很高的计算量;
松耦合是把VO处理后获得的变换矩阵和IMU进行融合,这样做优点是计算量小但是会带来累计误差。
下面是对经典的VIO框架进行一个分类:

地图点的构建方法有哪些
(1)三角化: 在ORB SLAM2中是根据三角化的方法确定地图点的,利用匹配好的两个点构建AX=b的方程,然后利用SVD分解取最小奇异值对应的特征向量作为地图点坐标,参考多视图几何总结——三角形法
(2)深度滤波器: 在SVO中是利用深度滤波器进行种子点深度更新,当种子点深度收敛后就加入地图构建地图点。
(在LSD中好像没有维护地图点,不断维护的是关键帧上的深度图)
如果对于一个3D点,我们在连续帧之间形成了2D特征点之间的匹配,但是这个匹配中可能存在错误的匹配。请问你如何去构建3D点?
先想到的是用RANSAC方法进行连续帧之间的位姿估计,然后用内点三角化恢复地图点,具体一点说使用RANSAC估计基础矩阵F的算法步骤如下:
(1)从匹配的点对中选择8个点,使用8点法估算出基础矩阵F
(2)计算其余的点对到其对应对极线的距离,如果距离\(d_n \leq d\),则该点为内点,否则为外点。记下符合该条件的内点的个数为\(m_i\)
(3)迭代k次,或者某次得到内点的数目占有的比例大于等于95%,则停止。选择最大的基础矩阵F作为最终的结果.
如果是利用非线性优化的方法获得位姿的话,可以在非线性优化代价函数中加入鲁棒核函数来减少无匹配所带来的误差,例如《视觉SLAM十四讲》里面提到的Huber核:
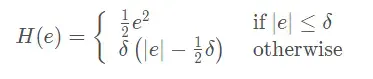
在《机器人的状态估计》一书总将这种方法称为M估计,核函数还包裹Cauchy核:
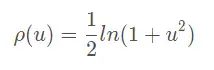
Geman-MeClure核
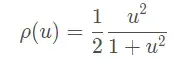
等。
RANSAC在选择最佳模型的时候用的判断准则是什么?
简单地说一般是选用具有最小残差和的模型作为最佳模型。