Scan Context: Egocentric Spatial Descriptor for Place Recognition within 3D Point Cloud Map
摘要
相比于视觉场景下使用特征描述符,使用结构信息来描述场景的研究相对较少。文章提出了Scan-Context,一种非直方图方法的全局描述符,用于全局定位。该方法直接记录了可见空间的3d结构,而不是依赖于直方图或先验的训练。此外,该方法还可用于计算两帧扫描的上下文之间的距离进行回环检测,其特点在于不受Lidar视点变化的影响,因此可以在反向访问或拐角等位置进行回环检测。
介绍
目前有在Lidar-based的场景识别方法中仍有两个issue尚待解决:
- 无论视点如何变化,描述符需要有旋转不变性
- 噪声处理,因为点云的分辨率随距离变化,而且法线受噪声影响
文章贡献:
- 高效的bin编码函数。与现有的点云描述符[7,10]不同,所提出的方法不需要计算容器中的点数,而是提出了一种更有效的容器编码功能来进行位置识别,此编码对点云密度和法线具有不变性
- 保存点云内部结构。如图1所示,矩阵的每个元素值仅由属于bin的点云确定,因此,与[9]不同,后者[9]将点的相对几何形状描述为直方图,并且会丢失点的绝对位置信息。我们的方法有意避免使用直方图来保留点云的绝对内部结构。这有利于提高判别能力,当距离得到后,还允许使得查询扫描帧与候选扫描视点对齐(实验中使用6\(\degree\)分辨率),因此本方法可用于检测反向的loop
- 高效的二阶段匹配算法。为了获得可行的搜索时间,我们为第一个最近邻搜索提供了一个旋转不变子描述符,并将其与成对相似性评分进行分层组合
Scan Context
对于室外环境,提出的描述符为“Scan Context”,主要受 “Shape Context [7]”(把某个keypoint附近的点云几何形状编码到图像中)启发。
他们的方法只是统计点的数量以得到点的分布,Scan Context方法与他们的不同之处在于,在每个bin中使用最大点的高度。使用高度的原因是可以有效地汇总周围结构的垂直形状,而无需进行大量计算即可分析点云的特征,此外,最大高度表示传感器可以看到周围结构的哪一部分。
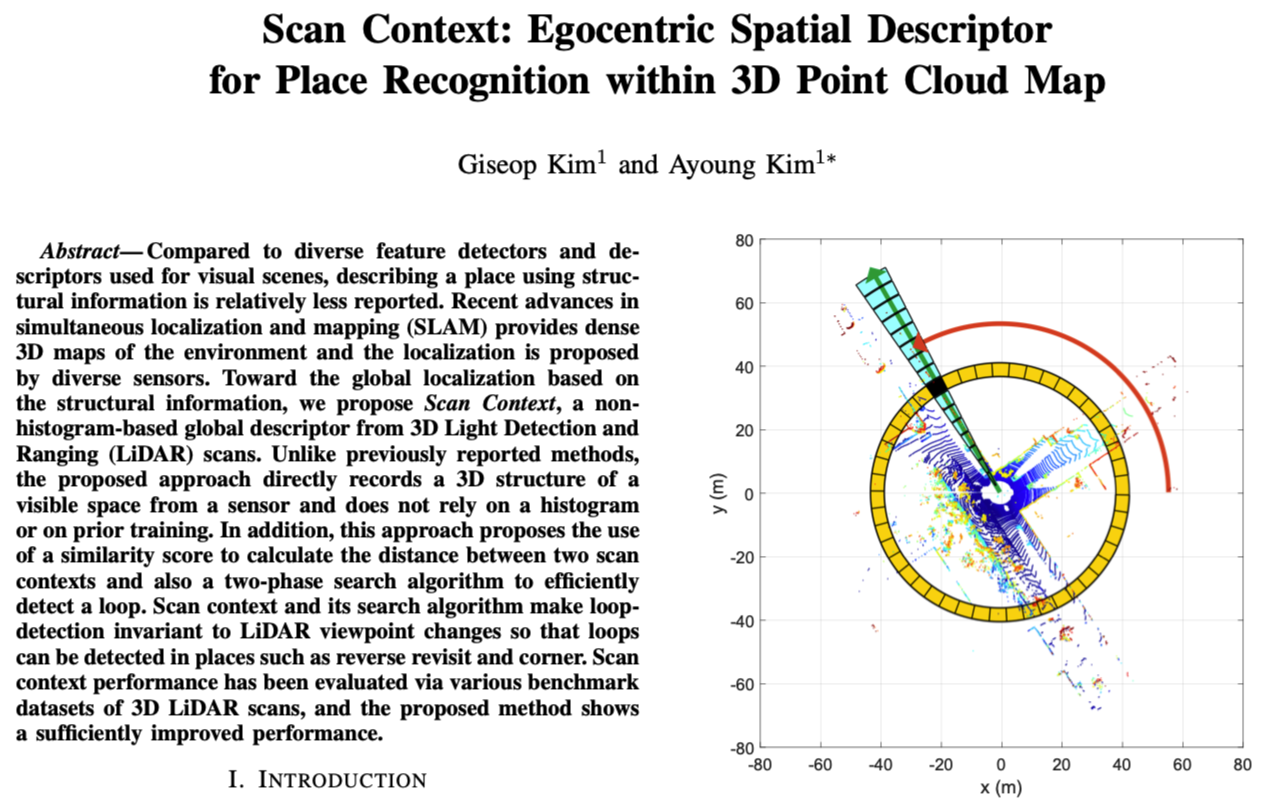
类似与Shape Context,我们首先将3D扫描在传感器坐标系中按方位角和径向角划分,但以等距的方式如图1(a)所示。
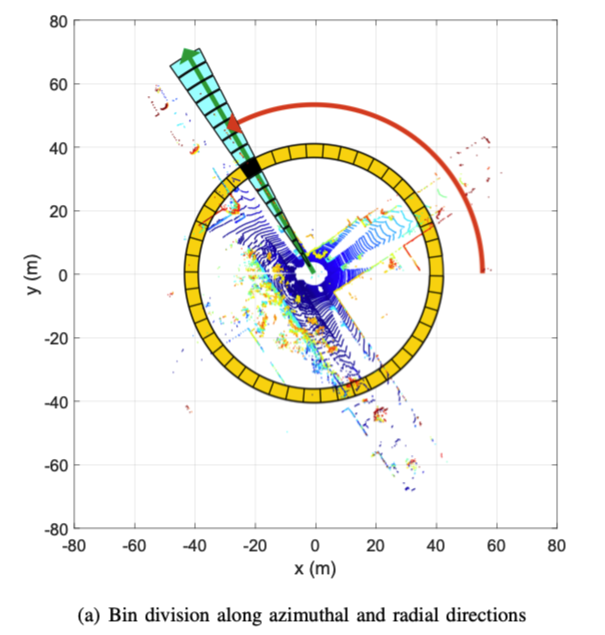
扫描的中心(Lidar)充当全局关键点,因此我们将扫描上下文称为以自我为中心的位置描述符,以下是符号描述:
- \(N_s\) 扇形的数量(图a蓝色块数量)
- \(N_r\) 环的数量 (图a红色块数量)
- \(\frac{L_{max}}{N_r}\) 放射间隔,其中\(L_{max}\)表示激光最远距离
- \(\frac{2\pi}{N_s}\) 扇形中心角
- 文章采用: \(N_s=60,N_r=20\)
因此,进行扫描上下文的第一步是将3D扫描的整个点划分为相互排斥的点云,如图1(a)所示。
其中,\(\mathcal{P}_{ij}\)表示第i个环(跟距离有关)第j个扇形(跟角度有关)中的点集。

由于点云是按固定间隔划分的,因此,距离传感器较远的bin的物理面积要大于附近的bin,但是,两者均被平等地编码为扫描上下文的单个像素。因此,扫描上下文补偿了由远点稀疏性引起的信息量不足,并将附近的动态对象视为稀疏噪声。
点云分区后,通过使用每个bin中的点云为每个bin分配单个实数值:

我们使用最大高度:

其中,z函数返回点p的高度值,对于空的bin,直接赋值为0。
例如,如图1(b)所示,扫描上下文中的蓝色像素表示对应于其bin的空间是空闲的,或者由于遮挡而未观察到

从上述过程中,扫描上下文I最终表示为Nr×Ns的矩阵为:
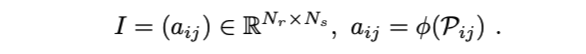
为了对平移实现鲁棒,我们通过root移位来进行扫描上下文增强,通过这样做,在轻微的运动扰动下从原始扫描获取各种扫描上下文变得可行。因为再次访问的时候,单个扫描上下文可能对平移运动的扫描的中心位置敏感。
为了克服这种情况,我们根据车道级别间隔将原始点云转换为\(N_{trans}\)邻居(本文中使用\(N_{trans} = 8\)),并将从这些偏移点云获得的扫描上下文存储在一起。
计算Scan Contexts的相似得分
给定一对“Scan Contexts” pair,我们需要一个距离来衡量两个地方的相似度,其中\(I^q,I^c\)分别是查询点云和候选点云的上下文。以列为主进行比较:即距离是相同索引处的列进行比较得到的差距。余弦距离用于计算同一索引处两个列向量之间的距离,\(c_{j}^q,c_{j}^c\)。
因此,距离函数为:
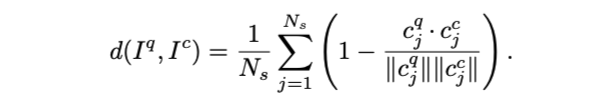
按列比较对于动态对象特别有效,但是,由于Lidar的视点在不同位置会发生变化,