前言
Scheduler是Cyber-RT的调度核心,是协程的调度载体。特别的,对于自动驾驶任务而言,任务调度的实时性发挥至关重要的作用,因此有必要对各种任务的优先级进行分类排序,如对于控制任务而言,需要单独分配CPU以供实时运行,Cyber-RT通过Scheduler来实现这种功能。
Cyber/Scheduler目录
1 | ├── BUILD |
Scheduler类图

两种策略
通过阅读上面的类图可以发现,Scheduler类是基类,其拥有两个子类,分别为SchedulerClassic和SchedulerChoreography,分别对应两种策略,Classic(经典)策略与Choreophgray(编排)策略。两者并不是互斥关系,后者可看作对前者的扩展。它们的介绍和示例可参考官方文档 Cyber RT Scheduler,这里暂不详细展开,下面的叙述以SchedulerClassic策略为主。
调度策略配置文件用protobuf定义,协议格式文件在cyber/proto目录下:scheduler_conf.proto,classic_conf.proto和choreography_conf.proto。调度策略配置文件在cyber/conf目录下。对于上面mkz_close_loop.pb.txt中的两个process group:compute_sched和control_sched,根据调度策略不同分别有两个版本

一个Scheduler实例
Scheduler是个单例,因此在程序启动时就被初始化了,尽管它不是程序的入口,但是从它却是系统子模块Component调度的管理者。
实例化
Scheduler的实例化过程由scheduler_factory.cc提供,其调用函数如下:
1 | Scheduler* Instance() { |
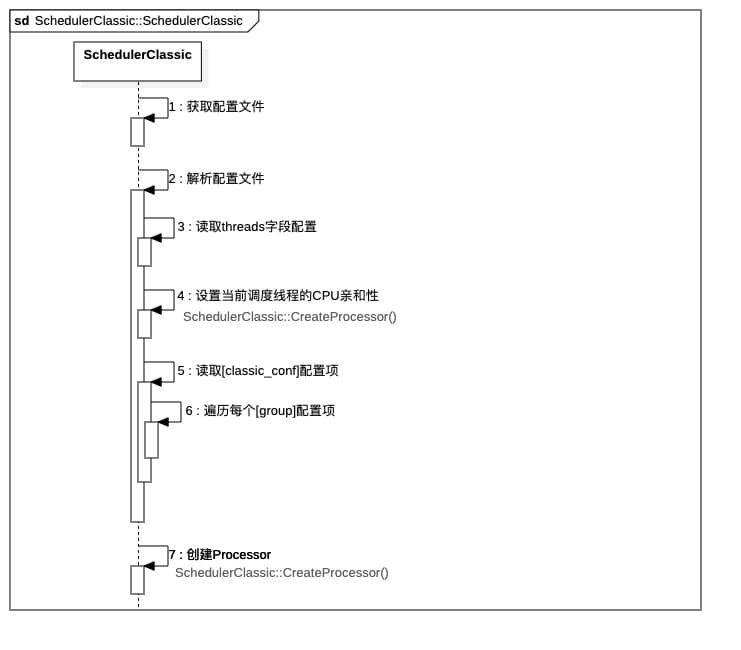
实例化主要做了几个事情:
- 获取配置文件
conf/xxxx.conf - 读取策略配置项
policy - 根据
policy配置项来选择实例化SchedulerClassic()还是SchedulerChoreography(),如果没有提供,则默认选择实例化SchedulerClassic() - 这个实现确保了线程安全,即
Scheduler单例只能被创建一个
以SchedulerClassic()为例,接下来看其实例化过程(构造函数):
1 | SchedulerClassic::SchedulerClassic(){ |
实例化过程中,有很多部分都与配置文件直接相关,这里我们以conf/example_sched_classic.conf为例展开:

我们从第4点开始看,首先是读取配置项process_level_cpuset_,根据配置文件,这个字符串一般填"0-7,16-23"形式的内容,表示当前调度线程可以由0-7,16-23号CPU核心来执行。最终实现这个功能的函数是Scheduler::ProcessLevelResourceControl(),其内部是通过glibc提供的接口pthread_setaffinity_np(pthread_self(), sizeof(set), &set);来实现对线程设置CPU亲和性。
注意配置文件中有两个优先级:
- 一个是
processor_prio,对应系统Linux中线程的优先级,即nice值,范围从-20到19,值越低优先级越高,默认值为0; - 另一个是task的
prio,它是Cyber RT中的协程调度的优先级,共20级,值越高优先越高
接下来第5点,简单来说就是读取每个[task]字段的配置项,并保存下来,其代码如下:
1 | classic_conf_ = cfg.scheduler_conf().classic_conf(); |
对应配置文件举例如下:

这里有一点需要注意的是,由于配置文件中每个[task]内部没有写明其所在的[group]名称,因此在读取配置的时候,通过task.set_group_name(group_name);进行了设置,这个group_name相当的重要,接下来会用到。
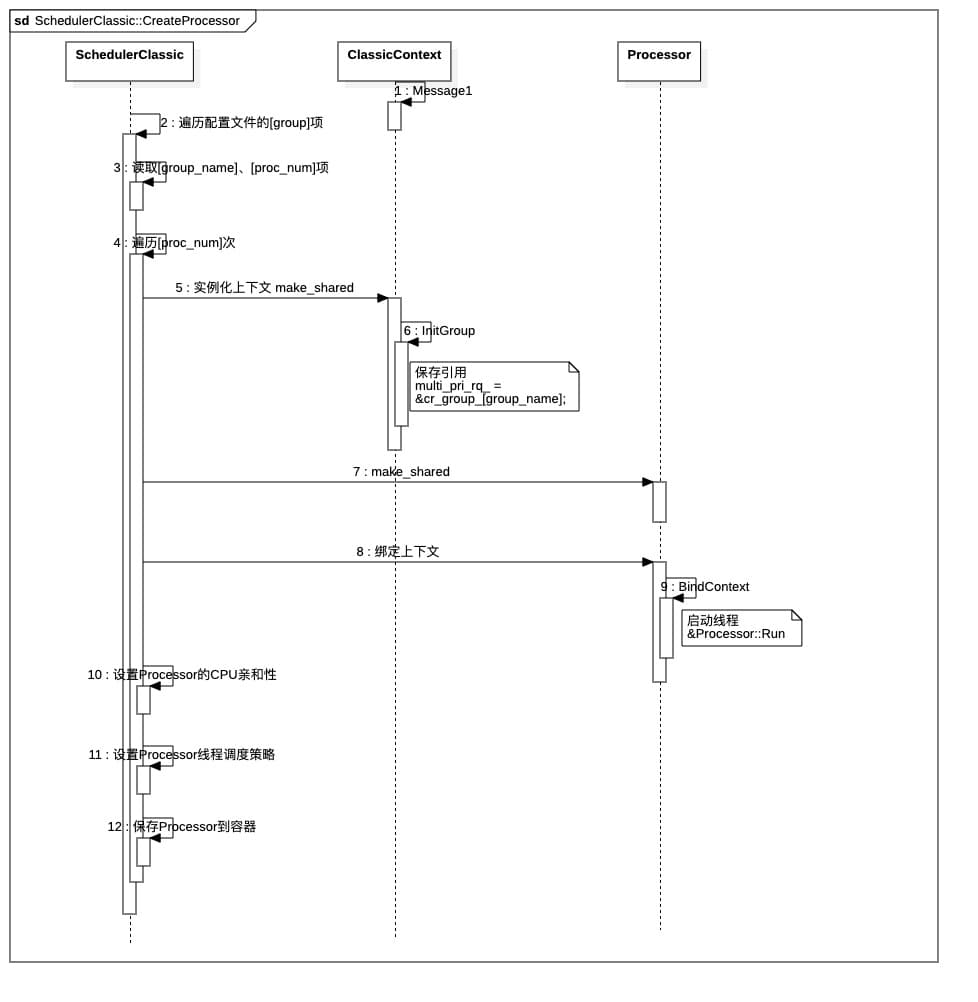
最后看第6点,为每个group创建对应数量的Processor,并设置相关策略,这是由函数SchedulerClassic::CreateProcessor()来实现的。
1 | void SchedulerClassic::CreateProcessor() { |
其中,通过SetSchedAffinity()函数对新创建的某个Processor对象内部的thread进行CPU亲和性设置,以实现CPU的分配,特别的,根据该group的affinity配置项,有两种CPU分配策略:
- range: 采用range策略,即每个Processor对象内部的thread都可以由
cpuset字段给定的范围内自由调度,即范围内的CPU都可以处理 - 1to1: 即每个Processor对象内部的thread只能对应一个CPU核心,
cpuset字段提供的是有多少个CPU可分配,但是个Processor对象内部的thread只能对应cpuset字段的第i个核心
以上是关于线程的CPU亲和性设置,接下来的一个关键问题是,创建这么多Processor,如何真正处理我们的任务?
代码片段中的3.3是关键,proc->BindContext(ctx)将新创建的ProcessorContext上下文保存到成员变量Processor::context_,然后开启线程来执行Processor::Run,该函数代码不长,就两句:
1 | void Processor::BindContext(const std::shared_ptr<ProcessorContext>& context) { |
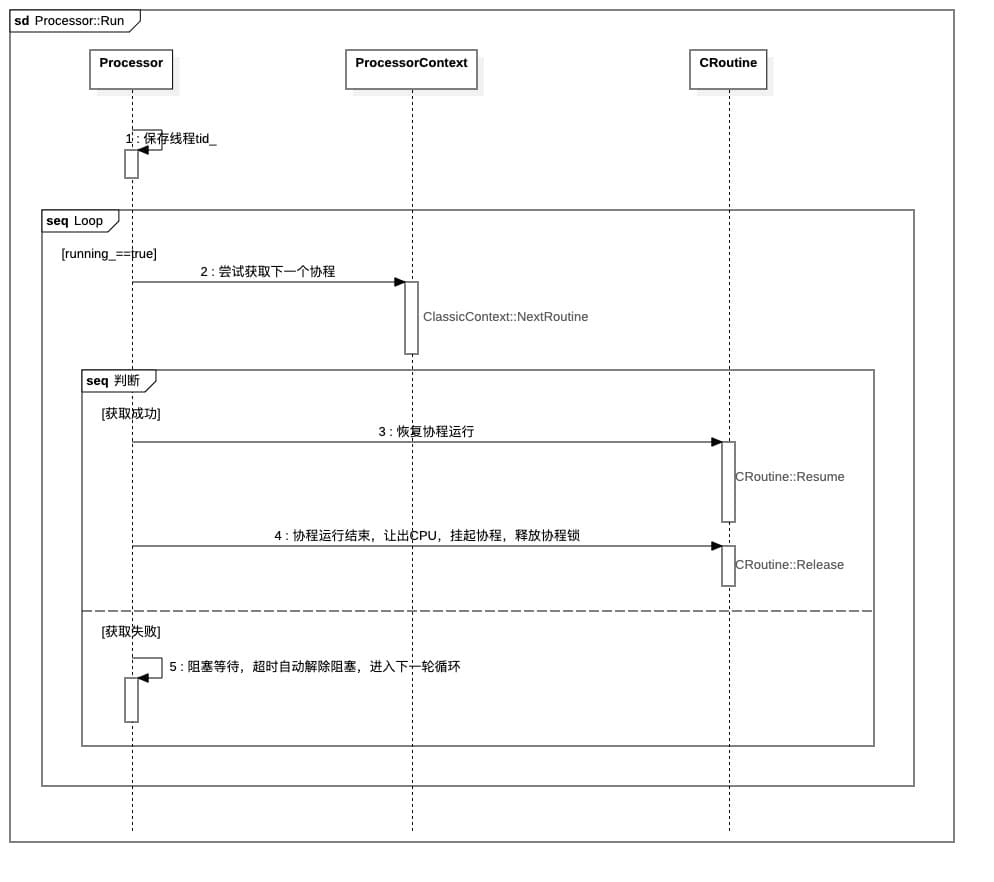
该函数首先保存传进来的ProcessorContext对象指针,然后启动了一个线程,看来Processor::Run这个线程就是实际执行任务的线程了,
1 | void Processor::Run() { |
Processor::Run这个线程不断的尝试从context_成员变量中获取协程,并恢复协程运行,一个协程的任务处理完后,继续从上下文获取下一个协程context_->NextRoutine();。至于这个协程的切入和切出,到后面协程篇章的时候再详细讨论。接下来,就要看看这个上下文成员变量context_是啥。
processor.h头文件内可知,成员变量context_声明如下:
1 | // ProcessorContext只是基类,实际保存下来的是 ClassicContext 或 ChoreographyContext |
即每个Processor对象内维护着一个ProcessorContext。
ProcessorContext
实际上,ProcessorContext只是基类,根据Scheduler的两种策略,分别对应着两种ProcessorContext,分别是:
- ClassicContext
- ChoreographyContext
uml类图如下:

接下来,以ClassicContext为主进行展开:
ProcessorContext实例化
ProcessorContext实例化不是在Processor内部进行,而是在上面提到的SchedulerClassic::CreateProcessor()函数中进行,具体代码片段为:
1 | auto ctx = std::make_shared<ClassicContext>(group_name); |
接下来,看ClassicContext的构造函数:
1 | ClassicContext::ClassicContext() |
ClassicContext类有两个构造函数,其中一个需要传参[group_name],另外一个不需传参。两个构造函数内部都调用了ClassicContext::InitGroup函数,该函数从全局静态容器中取对应[group_name]的引用并保存到ClassicContext类的成员变量中,目的是,当其他地方向全局静态容器添加元素时,直接调用ClassicContext类的成员变量即可访问到新增加的元素。该函数代码如下:
1 | void ClassicContext::InitGroup(const std::string& group_name) { |
ClassicContext的静态容器
上面提到ClassicContext类里面有几个全局静态容器,其在classic_context.h中声明如下:
1 | Class ClassicContext{ |
这几个容器都是Public的且静态的,所以其他地方可以直接往里面读写数据,而线程问题则通过rq_locks_容器和mtx_wq_容器进行加锁控制。
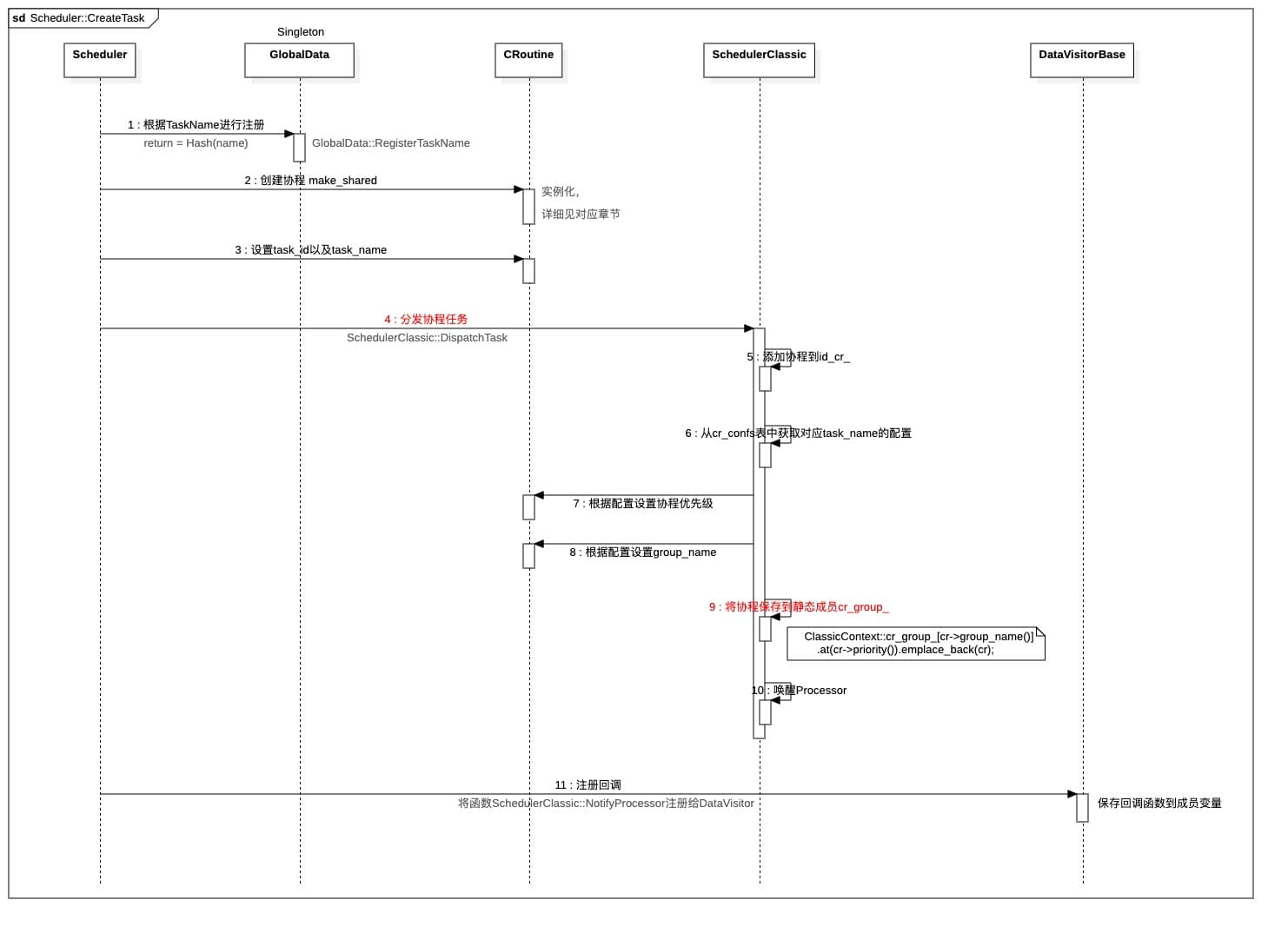
实际上,Scheduler要调度的任务,都保存到了这几个静态容器内部,如何存进去,以及存了什么进去,SchedulerClassic::DispatchTask函数给出了答案,该函数以一个协程指针作为参数,做了以下几个工作:
- 首先把这个新协程放入
Scheduler::id_cr_中, - 然后根据[协程名]查找保存的构造Scheduler单例时,产生的
cr_confs_中是否有该task对应的策略,如果有就根据策略设置该协程的[优先级]和[group_name] - 最后往
ClassicContext中的全局静态变量ClassicContext::cr_group_中对应该协程的[group_name]和优先级的队列中加入该协程 - 最后调用
ClassicContext::Notify(来通知该协程所属的组,让Processor::Run()结束阻塞,马上运行一次
这个函数,着重看以下代码块:
1 | bool SchedulerClassic::DispatchTask(const std::shared_ptr<CRoutine>& cr) { |
所以说,需要调度的协程,都通过这个函数,根据协程所在的组,把协程指针保存到ClassicContext::cr_group_静态变量中。
ClassicContext::cr_group数据结构
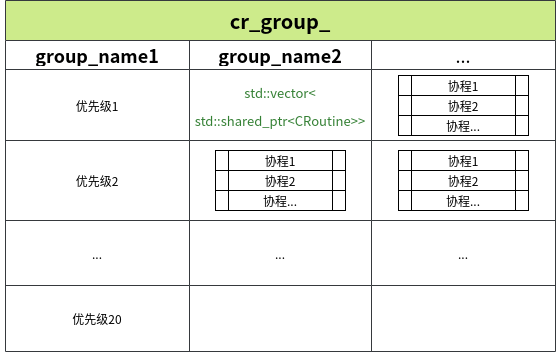
ClassicContext::cr_group_是一张大的表格,分为多个[group],每个[group]又分多个优先级,每个优先级对应着一个std::vector,vector内部存放着多个协程。
一个需要注意的点是,由于ClassicContext::cr_group_是静态变量,多个线程访问时会有data race的问题,因此cyber-rt增加了对应的锁ClassicContext::rq_locks_来解决。
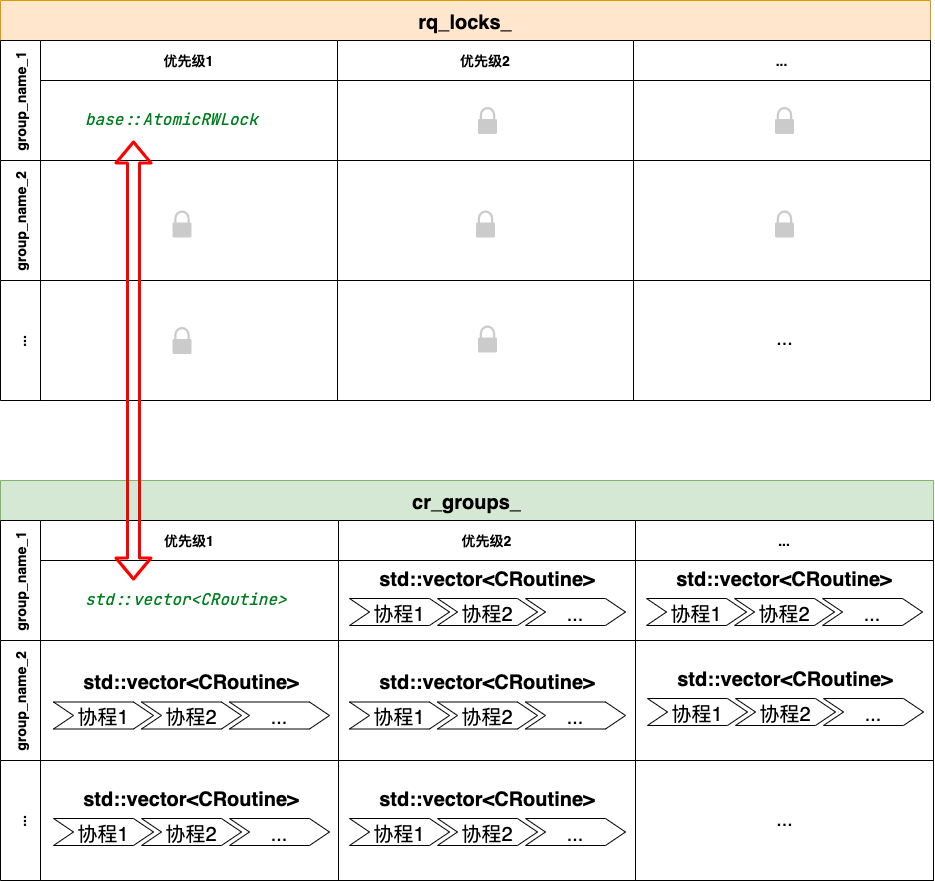
ClassicContext::rq_locks数据结构

显然,ClassicContext::rq_locks_内按group_name进行分组,每个组内又按优先级进行划分,因此,这里一个锁对应ClassicContext::cr_group_中的一个std::vector<CRoutine>,其对应关系如下图所示:
ClassicContext的动态容器
前面讨论了ClassicContext的静态成员变量,接下来我们看其类内动态成员变量。代码片段如下:
1 | class ClassicContext : public ProcessorContext { |
ClassicContext::multi_pri_rq队列
在函数ClassicContext::InitGroup中,将ClassicContext::cr_group_的某个组的引用赋值给了成员变量ClassicContext::multi_pri_rq_,因此,ClassicContext::multi_pri_rq_的数据结构如下:

ClassicContext::multi_pri_rq_与ClassicContext::cr_group_的映射关系如下:
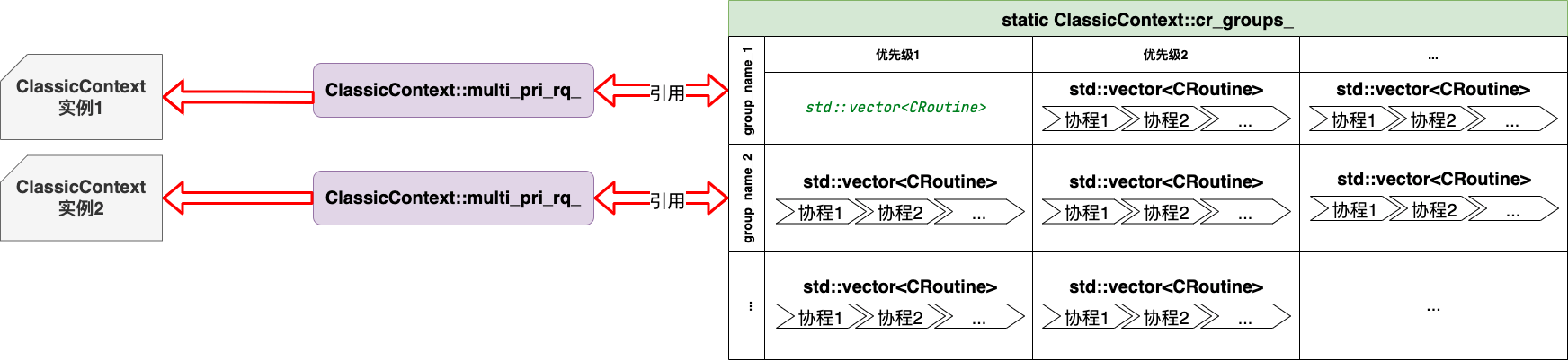
所以,通过向全局静态表ClassicContext::cr_group_写入协程后,可以通过ClassicContext::multi_pri_rq_来读取对应的协程,最后通过Processor::Run来完成协程的调用。
重要过程时序流图
创建SchedulerClassic实例
创建Processor并绑定上下文
创建Task并分配给Processor
Scheduler::CreateTask这个函数是Scheduler基类的函数,其内部会调用子类SchedulerClassic或SchedulerChoreography的DispatchTask()函数,最后将子类的NotifyProcessor函数注册给DataVistor对象,其详细的时序流程如下:
运转核心Processor::Run
唤醒机制SchedulerClassic::NotifyProcessor
