Real-time 3D Reconstruction at Scale using Voxel Hashing

摘要
由于实时消费深度相机的可用性,在线三维重建正在获得新的兴趣。基本问题以实时重叠的深度图作为输入,并将它们增量地融合到单个3D模型中。
这具有挑战性,特别是如何满足实时性能需求同时质量和规模性能都不下降。我们提供了一个在线系统,用于基于内存和速度高效的数据结构的大规模和精细的体积重建。
我们的系统使用简单的空间散列方案来压缩空间,并允许实时访问和更新隐式表面数据,而不需要常规或分层的网格数据结构。表面数据仅在观察到测量值的地方密集存储。此外,数据可以在哈希表或哈希表中有效地流式传输,从而在传感器运动期间实现进一步的可扩展性。我们展示了各种场景的交互式重建,重建细粒度的细节和大规模的环境。我们展示了我们的管道的所有部分如何从深度图预处理、摄像机姿态估计、深度图融合和表面渲染以商品图形硬件上的实时速率执行。并总结了与当前最先进的在线系统的比较,说明了改进的性能和重建质量。
介绍
我们提供了一个新的实时表面重建系统,该系统支持大规模的高质量重建。我们的方法具有体积方法的好处,但不需要内存受限的体素网格或分层数据结构的计算开销。我们的方法基于一种简单的内存和速度高效的空间哈希技术,该技术压缩空间,并允许实时融合参考隐式表面数据,而不需要分层数据结构。表面数据仅密集存储在观察测量的cell中。此外,数据可以在哈希表或哈希表中有效地流式传输,从而在传感器运动期间实现进一步的可扩展性。
相关工作
略
算法概述
我们扩展了Curless和Levoy[1996]的体积方法,通过将噪声深度图增量融合到存储器和速度高效的数据结构中,实时和大规模地重建高质量的3D表面。鉴于样本的简单累积平均值,Curless 和 Levoy 已被证明会产生令人信服的结果。该方法支持增量更新,对曲面没有拓扑假设,有效地逼近基于三角剖分的传感器的噪声特征。此外,虽然隐式表示,但可以很容易地提取存储的等值面。我们的方法解决了 Curless 和 Levoy 的主要缺点:支持高效的可扩展性。接下来,我们在描述我们的新方法之前回顾了Curless和Levoy方法
Curless&Levoy[1996]: A volumetric method for building complex models from range images
Implicit Volumetric Fusion(SDF和TSDF简介)
Curless 和 Levoy 的方法基于在体积数据结构中存储隐式符号距离场 (SDF)。让我们考虑一个规则的密集体素网格,并假设输入是一系列深度图。相对于这个网格(通常是网格的中心),深度传感器在某些原点初始化。首先,估计传感器的刚性六自由度(6DoF)自我运动,通常使用ICP的变体[Besl和McKay 1992;Chen和Medioni 1992]。
网格中的每个体素包含两个值:有符号距离和权重。对于单个深度图,通过均匀扫描视图截锥外的体积、剔除体素、将所有体素中心投影到深度图并更新存储的SDF值,将数据集成到网格中。投射到同一像素上的所有体素都被认为是深度样本足迹的一部分。在这些体素中的每一个中,存储从体素中心到观察到的表面测量的符号距离,正面距离、负面后面和表面界面处接近零。
为了减少计算成本,支持传感器运动和近似传感器噪声,Curless和Levoy引入了截断SDF (TSDF)的概念,它只存储观测表面周围区域的符号距离。该区域的大小可以适应,将传感器噪声近似为基于深度方差的高斯 [Chang et al.1994;阮等人。 2012]。仅使用加权平均值更新存储在这些区域体素中的TSDF值,以获得表面的估计。最后,作为每个深度样本足迹一部分的体素(在表面前面),但在截断区域之外明确标记为自由空间。这允许基于自由空间违规删除异常值。
Voxel Hashing
给定Curless和Levoy方法的截断曲面周围的sdf,存储在规则网格中的大多数数据被标记为自由空间或未观察到的空间,而不是表面数据。所以,关键挑战变成了如何设计数据结构来利用TSDF表示中的这种潜在稀疏性。
我们的方法特别避免了使用密集或分层数据结构,消除了对内存密集型规则网格的需求或计算复杂的层次结构进行体积融合。相反,我们使用一个简单的散列方案来紧凑存储、访问和更新隐式表面表示。提出了一种高效的基于gpu的哈希方法,大大减少了哈希条目冲突的数量。
我们的目标是构建一个实时系统,该系统采用空间哈希方案进行可扩展的体积重建。这对于 3D 重建来说并非易事,因为几何提前未知并且不断变化。因此,我们的散列技术必须支持动态分配和更新,同时最小化和解决潜在的散列条目冲突,而不需要包含的表面几何的先验知识。在接近我们数据结构的设计时,我们有目的地选择和扩展了一个简单的哈希方案 [Teschner et al.2003],虽然存在更复杂的方法,但我们凭经验表明我们的方法在速度、质量和可扩展性方面是有效的。
特性如下:
- 在保持表面分辨率的同时,有效压缩体积TSDF的能力,而不需要分层空间数据结构。
- 基于插入和更新,将新的TSDF样本有效地融合到哈希表中,同时最小化哈希碰撞。
- 体素块的去除和垃圾收集,而不需要对数据结构进行昂贵的重组。
- 主机和GPU之间体素块的轻量级双向流,允许无界重建
- 使用标准光线投射或多边形化操作有效地从数据结构中提取等值面,用于渲染和相机姿态估计
系统流程
我们的管道如图2所示。Central是一个散列表数据结构,它存储包含sdf的子块,称为体素块。哈希表中每个被占用的条目都指向一个已分配的体素块。在每个体素中,我们存储一个TSDF、权重和一个额外的颜色值。哈希表是非结构化的;也就是说,相邻的体素块不是存储在空间上的,而是可以存储在哈希表的不同部分。我们的哈希函数允许使用指定的(整数四舍五入)世界坐标高效地查找体素块。我们的哈希函数旨在最小化冲突的数量,并确保表中不存在重复项。
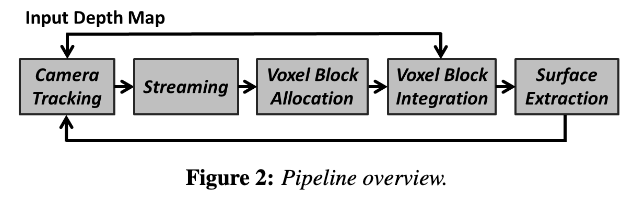
给定一个新的输入深度图,我们首先执行融合(也称为集成)。我们首先分配新的体素块,并根据输入深度图将块描述符插入哈希表。只分配已占用的体素,不存储空白空间。接下来,我们扫描每个分配的体素块,根据输入深度和颜色样本更新每个包含体素的SDF、颜色和权重。此外,我们对离等值面太远且不包含权重的体素块进行垃圾收集。这包括释放分配的内存以及从哈希表中删除体素。这些步骤确保我们的数据结构随着时间的推移保持稀疏。
融合(integration)后,我们从当前估计的相机姿态对隐式表面进行光线投射,以提取等值面,包括相关的颜色。提取的深度和颜色缓冲用作相机姿态估计的输入:给定下一个输入深度图,执行投影点平面ICP [Chen和Medioni 1992]来估计新的6DoF相机姿态。这确保了姿态估计是帧对模型进行的,而不是帧对帧,减轻了一些漂移问题(特别是对于小场景)[Newcombe等人]。2011]。最后,我们的算法实现了GPU和主机之间的双向流。哈希条目(以及相关的体素块)在它们的世界位置退出估计的摄像机视图截锥体时流式传输到主机。当重访区域时,先前流出的体素块也可以流回GPU数据结构。